In a previous article i briefly touched on FFTs. I mentioned that they are a faster way to perform polynomial interpolation. But FFTs are used for more than just polynomials. Specifically they are used for computing DFTs. A DFT is a system of linear equations that are related whose basis lies in C n \mathbb{C}^n C n
In order to motivate the need for the FFT, Let’s examine a 12-degree polynomial in whose basis lies in the real.
P ( x 0 ) = a 0 + a 1 x 0 + a 2 x 0 2 + a 3 x 0 3 + a 4 x 0 4 + a 5 x 0 5 + a 6 x 0 6 + a 7 x 0 7 + a 8 x 0 8 + a 9 x 0 9 + a 10 x 0 10 + a 11 x 0 11 P ( x 1 ) = a 0 + a 1 x 1 + a 2 x 1 2 + a 3 x 1 3 + a 4 x 1 4 + a 5 x 1 5 + a 6 x 1 6 + a 7 x 1 7 + a 8 x 1 8 + a 9 x 1 9 + a 10 x 1 10 + a 11 x 1 11 P ( x 2 ) = a 0 + a 1 x 2 + a 2 x 2 2 + a 3 x 2 3 + a 4 x 2 4 + a 5 x 2 5 + a 6 x 2 6 + a 7 x 2 7 + a 8 x 2 8 + a 9 x 2 9 + a 10 x 2 10 + a 11 x 2 11 P ( x 3 ) = a 0 + a 1 x 3 + a 2 x 3 2 + a 3 x 3 3 + a 4 x 3 4 + a 5 x 3 5 + a 6 x 3 6 + a 7 x 3 7 + a 8 x 3 8 + a 9 x 3 9 + a 10 x 3 10 + a 11 x 3 11 P ( x 4 ) = a 0 + a 1 x 4 + a 2 x 4 2 + a 3 x 4 3 + a 4 x 4 4 + a 5 x 4 5 + a 6 x 4 6 + a 7 x 4 7 + a 8 x 4 8 + a 9 x 4 9 + a 10 x 4 10 + a 11 x 4 11 P ( x 5 ) = a 0 + a 1 x 5 + a 2 x 5 2 + a 3 x 5 3 + a 4 x 5 4 + a 5 x 5 5 + a 6 x 5 6 + a 7 x 5 7 + a 8 x 5 8 + a 9 x 5 9 + a 10 x 5 10 + a 11 x 5 11 P ( x 6 ) = a 0 + a 1 x 6 + a 2 x 6 2 + a 3 x 6 3 + a 4 x 6 4 + a 5 x 6 5 + a 6 x 6 6 + a 7 x 6 7 + a 8 x 6 8 + a 9 x 6 9 + a 10 x 6 10 + a 11 x 6 11 P ( x 7 ) = a 0 + a 1 x 7 + a 2 x 7 2 + a 3 x 7 3 + a 4 x 7 4 + a 5 x 7 5 + a 6 x 7 6 + a 7 x 7 7 + a 8 x 7 8 + a 9 x 7 9 + a 10 x 7 10 + a 11 x 7 11 P ( x 8 ) = a 0 + a 1 x 8 + a 2 x 8 2 + a 3 x 8 3 + a 4 x 8 4 + a 5 x 8 5 + a 6 x 8 6 + a 7 x 8 7 + a 8 x 8 8 + a 9 x 8 9 + a 10 x 8 10 + a 11 x 8 11 P ( x 9 ) = a 0 + a 1 x 9 + a 2 x 9 2 + a 3 x 9 3 + a 4 x 9 4 + a 5 x 9 5 + a 6 x 9 6 + a 7 x 9 7 + a 8 x 9 8 + a 9 x 9 9 + a 10 x 9 10 + a 11 x 9 11 P ( x 10 ) = a 0 + a 1 x 10 + a 2 x 10 2 + a 3 x 10 3 + a 4 x 10 4 + a 5 x 10 5 + a 6 x 10 6 + a 7 x 10 7 + a 8 x 10 8 + a 9 x 10 9 + a 10 x 10 10 + a 11 x 10 11 P ( x 11 ) = a 0 + a 1 x 11 + a 2 x 11 2 + a 3 x 11 3 + a 4 x 11 4 + a 5 x 11 5 + a 6 x 11 6 + a 7 x 11 7 + a 8 x 11 8 + a 9 x 11 9 + a 10 x 11 10 + a 11 x 11 11 \begin{aligned}
P(x_0) &= a_0 + a_1x_0 + a_2x_0^2 + a_3x_0^3 + a_4x_0^4 + a_5x_0^5 + a_6x_0^6 + a_7x_0^7 + a_8x_0^8 + a_9x_0^9 + a_{10}x_0^{10} + a_{11}x_0^{11} \\ P(x_1) &= a_0 + a_1x_1 + a_2x_1^2 + a_3x_1^3 + a_4x_1^4 + a_5x_1^5 + a_6x_1^6 + a_7x_1^7 + a_8x_1^8 + a_9x_1^9 + a_{10}x_1^{10} + a_{11}x_1^{11} \\ P(x_2) &= a_0 + a_1x_2 + a_2x_2^2 + a_3x_2^3 + a_4x_2^4 + a_5x_2^5 + a_6x_2^6 + a_7x_2^7 + a_8x_2^8 + a_9x_2^9 + a_{10}x_2^{10} + a_{11}x_2^{11} \\ P(x_3) &= a_0 + a_1x_3 + a_2x_3^2 + a_3x_3^3 + a_4x_3^4 + a_5x_3^5 + a_6x_3^6 + a_7x_3^7 + a_8x_3^8 + a_9x_3^9 + a_{10}x_3^{10} + a_{11}x_3^{11} \\ P(x_4) &= a_0 + a_1x_4 + a_2x_4^2 + a_3x_4^3 + a_4x_4^4 + a_5x_4^5 + a_6x_4^6 + a_7x_4^7 + a_8x_4^8 + a_9x_4^9 + a_{10}x_4^{10} + a_{11}x_4^{11} \\ P(x_5) &= a_0 + a_1x_5 + a_2x_5^2 + a_3x_5^3 + a_4x_5^4 + a_5x_5^5 + a_6x_5^6 + a_7x_5^7 + a_8x_5^8 + a_9x_5^9 + a_{10}x_5^{10} + a_{11}x_5^{11} \\ P(x_6) &= a_0 + a_1x_6 + a_2x_6^2 + a_3x_6^3 + a_4x_6^4 + a_5x_6^5 + a_6x_6^6 + a_7x_6^7 + a_8x_6^8 + a_9x_6^9 + a_{10}x_6^{10} + a_{11}x_6^{11} \\ P(x_7) &= a_0 + a_1x_7 + a_2x_7^2 + a_3x_7^3 + a_4x_7^4 + a_5x_7^5 + a_6x_7^6 + a_7x_7^7 + a_8x_7^8 + a_9x_7^9 + a_{10}x_7^{10} + a_{11}x_7^{11} \\ P(x_8) &= a_0 + a_1x_8 + a_2x_8^2 + a_3x_8^3 + a_4x_8^4 + a_5x_8^5 + a_6x_8^6 + a_7x_8^7 + a_8x_8^8 + a_9x_8^9 + a_{10}x_8^{10} + a_{11}x_8^{11} \\ P(x_9) &= a_0 + a_1x_9 + a_2x_9^2 + a_3x_9^3 + a_4x_9^4 + a_5x_9^5 + a_6x_9^6 + a_7x_9^7 + a_8x_9^8 + a_9x_9^9 + a_{10}x_9^{10} + a_{11}x_9^{11} \\ P(x_{10}) &= a_0 + a_1x_{10} + a_2x_{10}^2 + a_3x_{10}^3 + a_4x_{10}^4 + a_5x_{10}^5 + a_6x_{10}^6 + a_7x_{10}^7 + a_8x_{10}^8 + a_9x_{10}^9 + a_{10}x_{10}^{10} + a_{11}x_{10}^{11} \\ P(x_{11}) &= a_0 + a_1x_{11} + a_2x_{11}^2 + a_3x_{11}^3 + a_4x_{11}^4 + a_5x_{11}^5 + a_6x_{11}^6 + a_7x_{11}^7 + a_8x_{11}^8 + a_9x_{11}^9 + a_{10}x_{11}^{10} + a_{11}x_{11}^{11} \\ \end{aligned} P ( x 0 ) P ( x 1 ) P ( x 2 ) P ( x 3 ) P ( x 4 ) P ( x 5 ) P ( x 6 ) P ( x 7 ) P ( x 8 ) P ( x 9 ) P ( x 10 ) P ( x 11 ) = a 0 + a 1 x 0 + a 2 x 0 2 + a 3 x 0 3 + a 4 x 0 4 + a 5 x 0 5 + a 6 x 0 6 + a 7 x 0 7 + a 8 x 0 8 + a 9 x 0 9 + a 10 x 0 10 + a 11 x 0 11 = a 0 + a 1 x 1 + a 2 x 1 2 + a 3 x 1 3 + a 4 x 1 4 + a 5 x 1 5 + a 6 x 1 6 + a 7 x 1 7 + a 8 x 1 8 + a 9 x 1 9 + a 10 x 1 10 + a 11 x 1 11 = a 0 + a 1 x 2 + a 2 x 2 2 + a 3 x 2 3 + a 4 x 2 4 + a 5 x 2 5 + a 6 x 2 6 + a 7 x 2 7 + a 8 x 2 8 + a 9 x 2 9 + a 10 x 2 10 + a 11 x 2 11 = a 0 + a 1 x 3 + a 2 x 3 2 + a 3 x 3 3 + a 4 x 3 4 + a 5 x 3 5 + a 6 x 3 6 + a 7 x 3 7 + a 8 x 3 8 + a 9 x 3 9 + a 10 x 3 10 + a 11 x 3 11 = a 0 + a 1 x 4 + a 2 x 4 2 + a 3 x 4 3 + a 4 x 4 4 + a 5 x 4 5 + a 6 x 4 6 + a 7 x 4 7 + a 8 x 4 8 + a 9 x 4 9 + a 10 x 4 10 + a 11 x 4 11 = a 0 + a 1 x 5 + a 2 x 5 2 + a 3 x 5 3 + a 4 x 5 4 + a 5 x 5 5 + a 6 x 5 6 + a 7 x 5 7 + a 8 x 5 8 + a 9 x 5 9 + a 10 x 5 10 + a 11 x 5 11 = a 0 + a 1 x 6 + a 2 x 6 2 + a 3 x 6 3 + a 4 x 6 4 + a 5 x 6 5 + a 6 x 6 6 + a 7 x 6 7 + a 8 x 6 8 + a 9 x 6 9 + a 10 x 6 10 + a 11 x 6 11 = a 0 + a 1 x 7 + a 2 x 7 2 + a 3 x 7 3 + a 4 x 7 4 + a 5 x 7 5 + a 6 x 7 6 + a 7 x 7 7 + a 8 x 7 8 + a 9 x 7 9 + a 10 x 7 10 + a 11 x 7 11 = a 0 + a 1 x 8 + a 2 x 8 2 + a 3 x 8 3 + a 4 x 8 4 + a 5 x 8 5 + a 6 x 8 6 + a 7 x 8 7 + a 8 x 8 8 + a 9 x 8 9 + a 10 x 8 10 + a 11 x 8 11 = a 0 + a 1 x 9 + a 2 x 9 2 + a 3 x 9 3 + a 4 x 9 4 + a 5 x 9 5 + a 6 x 9 6 + a 7 x 9 7 + a 8 x 9 8 + a 9 x 9 9 + a 10 x 9 10 + a 11 x 9 11 = a 0 + a 1 x 10 + a 2 x 10 2 + a 3 x 10 3 + a 4 x 10 4 + a 5 x 10 5 + a 6 x 10 6 + a 7 x 10 7 + a 8 x 10 8 + a 9 x 10 9 + a 10 x 10 10 + a 11 x 10 11 = a 0 + a 1 x 11 + a 2 x 11 2 + a 3 x 11 3 + a 4 x 11 4 + a 5 x 11 5 + a 6 x 11 6 + a 7 x 11 7 + a 8 x 11 8 + a 9 x 11 9 + a 10 x 11 10 + a 11 x 11 11 It’s clear from writing out this expression that the complexity of calculating each P ( x i ) P(x_i) P ( x i ) x ∈ { 0 , … , n − 1 } x \in \{0, \dots, n-1 \} x ∈ { 0 , … , n − 1 } O ( N 2 ) O(N^2) O ( N 2 ) matrix multiplication :
[ 1 x 0 x 0 2 x 0 3 x 0 4 x 0 5 x 0 6 x 0 7 x 0 8 x 0 9 x 0 10 x 0 11 1 x 1 x 1 2 x 1 3 x 1 4 x 1 5 x 1 6 x 1 7 x 1 8 x 1 9 x 1 10 x 1 11 1 x 2 x 2 2 x 2 3 x 2 4 x 2 5 x 2 6 x 2 7 x 2 8 x 2 9 x 2 10 x 2 11 1 x 3 x 3 2 x 3 3 x 3 4 x 3 5 x 3 6 x 3 7 x 3 8 x 3 9 x 3 10 x 3 11 1 x 4 x 4 2 x 4 3 x 4 4 x 4 5 x 4 6 x 4 7 x 4 8 x 4 9 x 4 10 x 4 11 1 x 5 x 5 2 x 5 3 x 5 4 x 5 5 x 5 6 x 5 7 x 5 8 x 5 9 x 5 10 x 5 11 1 x 6 x 6 2 x 6 3 x 6 4 x 6 5 x 6 6 x 6 7 x 6 8 x 6 9 x 6 10 x 6 11 1 x 7 x 7 2 x 7 3 x 7 4 x 7 5 x 7 6 x 7 7 x 7 8 x 7 9 x 7 10 x 7 11 1 x 8 x 8 2 x 8 3 x 8 4 x 8 5 x 8 6 x 8 7 x 8 8 x 8 9 x 8 10 x 8 11 1 x 9 x 9 2 x 9 3 x 9 4 x 9 5 x 9 6 x 9 7 x 9 8 x 9 9 x 9 10 x 9 11 1 x 10 x 10 2 x 10 3 x 10 4 x 10 5 x 10 6 x 10 7 x 10 8 x 10 9 x 10 10 x 10 11 1 x 11 x 11 2 x 11 3 x 11 4 x 11 5 x 11 6 x 11 7 x 11 8 x 11 9 x 11 10 x 11 11 ] [ a 0 a 1 a 2 a 3 a 4 a 5 a 6 a 7 a 8 a 9 a 10 a 11 ] = [ P ( x 0 ) P ( x 1 ) P ( x 2 ) P ( x 3 ) P ( x 4 ) P ( x 5 ) P ( x 6 ) P ( x 7 ) P ( x 8 ) P ( x 9 ) P ( x 10 ) P ( x 11 ) ] \begin{bmatrix} 1 & x_0 & x_0^2 & x_0^3 & x_0^4 & x_0^5 & x_0^6 & x_0^7 & x_0^8 & x_0^9 & x_0^{10} & x_0^{11} \\ 1 & x_1 & x_1^2 & x_1^3 & x_1^4 & x_1^5 & x_1^6 & x_1^7 & x_1^8 & x_1^9 & x_1^{10} & x_1^{11} \\ 1 & x_2 & x_2^2 & x_2^3 & x_2^4 & x_2^5 & x_2^6 & x_2^7 & x_2^8 & x_2^9 & x_2^{10} & x_2^{11} \\ 1 & x_3 & x_3^2 & x_3^3 & x_3^4 & x_3^5 & x_3^6 & x_3^7 & x_3^8 & x_3^9 & x_3^{10} & x_3^{11} \\ 1 & x_4 & x_4^2 & x_4^3 & x_4^4 & x_4^5 & x_4^6 & x_4^7 & x_4^8 & x_4^9 & x_4^{10} & x_4^{11} \\ 1 & x_5 & x_5^2 & x_5^3 & x_5^4 & x_5^5 & x_5^6 & x_5^7 & x_5^8 & x_5^9 & x_5^{10} & x_5^{11} \\ 1 & x_6 & x_6^2 & x_6^3 & x_6^4 & x_6^5 & x_6^6 & x_6^7 & x_6^8 & x_6^9 & x_6^{10} & x_6^{11} \\ 1 & x_7 & x_7^2 & x_7^3 & x_7^4 & x_7^5 & x_7^6 & x_7^7 & x_7^8 & x_7^9 & x_7^{10} & x_7^{11} \\ 1 & x_8 & x_8^2 & x_8^3 & x_8^4 & x_8^5 & x_8^6 & x_8^7 & x_8^8 & x_8^9 & x_8^{10} & x_8^{11} \\ 1 & x_9 & x_9^2 & x_9^3 & x_9^4 & x_9^5 & x_9^6 & x_9^7 & x_9^8 & x_9^9 & x_9^{10} & x_9^{11} \\ 1 & x_{10} & x_{10}^2 & x_{10}^3 & x_{10}^4 & x_{10}^5 & x_{10}^6 & x_{10}^7 & x_{10}^8 & x_{10}^9 & x_{10}^{10} & x_{10}^{11} \\ 1 & x_{11} & x_{11}^2 & x_{11}^3 & x_{11}^4 & x_{11}^5 & x_{11}^6 & x_{11}^7 & x_{11}^8 & x_{11}^9 & x_{11}^{10} & x_{11}^{11} \\
\end{bmatrix} \begin{bmatrix} a_0 \\ a_1 \\ a_2 \\ a_3 \\ a_4 \\ a_5 \\ a_6 \\ a_7 \\ a_8 \\ a_9 \\ a_{10} \\ a_{11} \\ \end{bmatrix} = \begin{bmatrix} P(x_0) \\ P(x_1) \\ P(x_2) \\ P(x_3) \\ P(x_4) \\ P(x_5) \\ P(x_6) \\ P(x_7) \\ P(x_8) \\ P(x_9) \\ P(x_{10}) \\ P(x_{11}) \\ \end{bmatrix} 1 1 1 1 1 1 1 1 1 1 1 1 x 0 x 1 x 2 x 3 x 4 x 5 x 6 x 7 x 8 x 9 x 10 x 11 x 0 2 x 1 2 x 2 2 x 3 2 x 4 2 x 5 2 x 6 2 x 7 2 x 8 2 x 9 2 x 10 2 x 11 2 x 0 3 x 1 3 x 2 3 x 3 3 x 4 3 x 5 3 x 6 3 x 7 3 x 8 3 x 9 3 x 10 3 x 11 3 x 0 4 x 1 4 x 2 4 x 3 4 x 4 4 x 5 4 x 6 4 x 7 4 x 8 4 x 9 4 x 10 4 x 11 4 x 0 5 x 1 5 x 2 5 x 3 5 x 4 5 x 5 5 x 6 5 x 7 5 x 8 5 x 9 5 x 10 5 x 11 5 x 0 6 x 1 6 x 2 6 x 3 6 x 4 6 x 5 6 x 6 6 x 7 6 x 8 6 x 9 6 x 10 6 x 11 6 x 0 7 x 1 7 x 2 7 x 3 7 x 4 7 x 5 7 x 6 7 x 7 7 x 8 7 x 9 7 x 10 7 x 11 7 x 0 8 x 1 8 x 2 8 x 3 8 x 4 8 x 5 8 x 6 8 x 7 8 x 8 8 x 9 8 x 10 8 x 11 8 x 0 9 x 1 9 x 2 9 x 3 9 x 4 9 x 5 9 x 6 9 x 7 9 x 8 9 x 9 9 x 10 9 x 11 9 x 0 10 x 1 10 x 2 10 x 3 10 x 4 10 x 5 10 x 6 10 x 7 10 x 8 10 x 9 10 x 10 10 x 11 10 x 0 11 x 1 11 x 2 11 x 3 11 x 4 11 x 5 11 x 6 11 x 7 11 x 8 11 x 9 11 x 10 11 x 11 11 a 0 a 1 a 2 a 3 a 4 a 5 a 6 a 7 a 8 a 9 a 10 a 11 = P ( x 0 ) P ( x 1 ) P ( x 2 ) P ( x 3 ) P ( x 4 ) P ( x 5 ) P ( x 6 ) P ( x 7 ) P ( x 8 ) P ( x 9 ) P ( x 10 ) P ( x 11 ) This matrix is also known as the vandermonde matrix . The vandermonde matrix is invertible, since it is a square matrix with distinct elements. This equation can therefore be re-arranged allowing us to derive the coefficients a i a_i a i P ( x i ) P(x_i) P ( x i )
a = V − 1 P a = V^{-1}P a = V − 1 P This is an alternative algebraic form of polynomial interpolation, other forms include Lagrange polynomials, Newton’s polynomials etc. Unfortunately, performing either operations, whether polynomial evaluation or interpolation leads to a complexity of O ( N 2 ) O(N^2) O ( N 2 )
The Fast Fourier Transform provides a way to transform the complexity of computing a DFT of size N N N O ( N 2 ) O(N^2) O ( N 2 ) change of basis , i.e rewrite the coordinates of our polynomial to be elements of a cyclic group. Such that they are indexed by successive powers of the generator of this cyclic group. Thus we get the DFT
X ( j ) = ∑ k = 0 N − 1 A ( k ) ⋅ ω j k , j = 0 , 1 , … N − 1. \begin{equation}
X(j) = \sum_{k = 0}^{N-1} A(k)\cdot \omega^{jk}, \quad j = 0,1,\dots N-1. \tag{1}
\end{equation} X ( j ) = k = 0 ∑ N − 1 A ( k ) ⋅ ω j k , j = 0 , 1 , … N − 1. ( 1 ) where ω = e 2 π i / N \omega = e^{2\pi i/N} ω = e 2 π i / N ω N = 1 \omega^N = 1 ω N = 1 N = 12 N = 12 N = 12
[ ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 1 ω 2 ω 3 ω 4 ω 5 ω 6 ω 7 ω 8 ω 9 ω 10 ω 11 ω 0 ω 2 ω 4 ω 6 ω 8 ω 10 ω 12 ω 14 ω 16 ω 18 ω 20 ω 22 ω 0 ω 3 ω 6 ω 9 ω 12 ω 15 ω 18 ω 21 ω 24 ω 27 ω 30 ω 33 ω 0 ω 4 ω 8 ω 12 ω 16 ω 20 ω 24 ω 28 ω 32 ω 36 ω 40 ω 44 ω 0 ω 5 ω 10 ω 15 ω 20 ω 25 ω 30 ω 35 ω 40 ω 45 ω 50 ω 55 ω 0 ω 6 ω 12 ω 18 ω 24 ω 30 ω 36 ω 42 ω 48 ω 54 ω 60 ω 66 ω 0 ω 7 ω 14 ω 21 ω 28 ω 35 ω 42 ω 49 ω 56 ω 63 ω 70 ω 77 ω 0 ω 8 ω 16 ω 24 ω 32 ω 40 ω 48 ω 56 ω 64 ω 72 ω 80 ω 88 ω 0 ω 9 ω 18 ω 27 ω 36 ω 45 ω 54 ω 63 ω 72 ω 81 ω 90 ω 99 ω 0 ω 10 ω 20 ω 30 ω 40 ω 50 ω 60 ω 70 ω 80 ω 90 ω 100 ω 110 ω 0 ω 11 ω 22 ω 33 ω 44 ω 55 ω 66 ω 77 ω 88 ω 99 ω 110 ω 121 ] [ a 0 a 1 a 2 a 3 a 4 a 5 a 6 a 7 a 8 a 9 a 10 a 11 ] = [ P ( x 0 ) P ( x 1 ) P ( x 2 ) P ( x 3 ) P ( x 4 ) P ( x 5 ) P ( x 6 ) P ( x 7 ) P ( x 8 ) P ( x 9 ) P ( x 10 ) P ( x 11 ) ] \begin{bmatrix}\omega^0 & \omega^0 & \omega^0 & \omega^0 & \omega^0 & \omega^0 & \omega^0 & \omega^0 & \omega^0 & \omega^0 & \omega^0 & \omega^0 \\\omega^0 & \omega^1 & \omega^2 & \omega^3 & \omega^4 & \omega^5 & \omega^6 & \omega^7 & \omega^8 & \omega^9 & \omega^{10} & \omega^{11} \\\omega^0 & \omega^2 & \omega^4 & \omega^6 & \omega^{8} & \omega^{10} & \omega^{12} & \omega^{14} & \omega^{16} & \omega^{18} & \omega^{20} & \omega^{22} \\\omega^{0} & \omega^{3} & \omega^{6} & \omega^{9} & \omega^{12} & \omega^{15} & \omega^{18} & \omega^{21} & \omega^{24} & \omega^{27} & \omega^{30} & \omega^{33} \\\omega^{0} & \omega^{4} & \omega^{8} & \omega^{12} & \omega^{16} & \omega^{20} & \omega^{24} & \omega^{28} & \omega^{32} & \omega^{36} & \omega^{40} & \omega^{44} \\\omega^{0} & \omega^{5} & \omega^{10} & \omega^{15} & \omega^{20} & \omega^{25} & \omega^{30} & \omega^{35} & \omega^{40} & \omega^{45} & \omega^{50} & \omega^{55} \\\omega^{0} & \omega^{6} & \omega^{12} & \omega^{18} & \omega^{24} & \omega^{30} & \omega^{36} & \omega^{42} & \omega^{48} & \omega^{54} & \omega^{60} & \omega^{66} \\\omega^{0} & \omega^{7} & \omega^{14} & \omega^{21} & \omega^{28} & \omega^{35} & \omega^{42} & \omega^{49} & \omega^{56} & \omega^{63} & \omega^{70} & \omega^{77} \\\omega^{0} & \omega^{8} & \omega^{16} & \omega^{24} & \omega^{32} & \omega^{40} & \omega^{48} & \omega^{56} & \omega^{64} & \omega^{72} & \omega^{80} & \omega^{88} \\\omega^{0} & \omega^{9} & \omega^{18} & \omega^{27} & \omega^{36} & \omega^{45} & \omega^{54} & \omega^{63} & \omega^{72} & \omega^{81} & \omega^{90} & \omega^{99} \\\omega^{0} & \omega^{10} & \omega^{20} & \omega^{30} & \omega^{40} & \omega^{50} & \omega^{60} & \omega^{70} & \omega^{80} & \omega^{90} & \omega^{100} & \omega^{110} \\\omega^{0} & \omega^{11} & \omega^{22} & \omega^{33} & \omega^{44} & \omega^{55} & \omega^{66} & \omega^{77} & \omega^{88} & \omega^{99} & \omega^{110} & \omega^{121} \\\end{bmatrix}\begin{bmatrix}
a_0 \\
a_1 \\
a_2 \\
a_3 \\
a_4 \\
a_5 \\
a_6 \\
a_7 \\
a_8 \\
a_9 \\
a_{10} \\
a_{11} \\
\end{bmatrix}
=
\begin{bmatrix}
P(x_0) \\
P(x_1) \\
P(x_2) \\
P(x_3) \\
P(x_4) \\
P(x_5) \\
P(x_6) \\
P(x_7) \\
P(x_8) \\
P(x_9) \\
P(x_{10}) \\
P(x_{11}) \\
\end{bmatrix} ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 1 ω 2 ω 3 ω 4 ω 5 ω 6 ω 7 ω 8 ω 9 ω 10 ω 11 ω 0 ω 2 ω 4 ω 6 ω 8 ω 10 ω 12 ω 14 ω 16 ω 18 ω 20 ω 22 ω 0 ω 3 ω 6 ω 9 ω 12 ω 15 ω 18 ω 21 ω 24 ω 27 ω 30 ω 33 ω 0 ω 4 ω 8 ω 12 ω 16 ω 20 ω 24 ω 28 ω 32 ω 36 ω 40 ω 44 ω 0 ω 5 ω 10 ω 15 ω 20 ω 25 ω 30 ω 35 ω 40 ω 45 ω 50 ω 55 ω 0 ω 6 ω 12 ω 18 ω 24 ω 30 ω 36 ω 42 ω 48 ω 54 ω 60 ω 66 ω 0 ω 7 ω 14 ω 21 ω 28 ω 35 ω 42 ω 49 ω 56 ω 63 ω 70 ω 77 ω 0 ω 8 ω 16 ω 24 ω 32 ω 40 ω 48 ω 56 ω 64 ω 72 ω 80 ω 88 ω 0 ω 9 ω 18 ω 27 ω 36 ω 45 ω 54 ω 63 ω 72 ω 81 ω 90 ω 99 ω 0 ω 10 ω 20 ω 30 ω 40 ω 50 ω 60 ω 70 ω 80 ω 90 ω 100 ω 110 ω 0 ω 11 ω 22 ω 33 ω 44 ω 55 ω 66 ω 77 ω 88 ω 99 ω 110 ω 121 a 0 a 1 a 2 a 3 a 4 a 5 a 6 a 7 a 8 a 9 a 10 a 11 = P ( x 0 ) P ( x 1 ) P ( x 2 ) P ( x 3 ) P ( x 4 ) P ( x 5 ) P ( x 6 ) P ( x 7 ) P ( x 8 ) P ( x 9 ) P ( x 10 ) P ( x 11 ) simplifying since ω k = ω k m o d N \omega^k = \omega^{k \mod N} ω k = ω k mod N
[ 1 1 1 1 1 1 1 1 1 1 1 1 1 ω 1 ω 2 ω 3 ω 4 ω 5 ω 6 ω 7 ω 8 ω 9 ω 10 ω 11 1 ω 2 ω 4 ω 6 ω 8 ω 10 1 ω 2 ω 4 ω 6 ω 8 ω 10 1 ω 3 ω 6 ω 9 1 ω 3 ω 6 ω 9 1 ω 3 ω 6 ω 9 1 ω 4 ω 8 1 ω 4 ω 8 1 ω 4 ω 8 1 ω 4 ω 8 1 ω 5 ω 10 ω 3 ω 8 ω 1 ω 6 ω 11 ω 4 ω 9 ω 2 ω 7 1 ω 6 1 ω 6 1 ω 6 1 ω 6 1 ω 6 1 ω 6 1 ω 7 ω 2 ω 9 ω 4 ω 11 ω 6 ω 1 ω 8 ω 3 ω 10 ω 5 1 ω 8 ω 4 1 ω 8 ω 4 1 ω 8 ω 4 1 ω 8 ω 4 1 ω 9 ω 6 ω 3 1 ω 9 ω 6 ω 3 1 ω 9 ω 6 ω 3 1 ω 10 ω 8 ω 6 ω 4 ω 2 1 ω 10 ω 8 ω 6 ω 4 ω 2 1 ω 11 ω 10 ω 9 ω 8 ω 7 ω 6 ω 5 ω 4 ω 3 ω 2 ω 1 ] [ a 0 a 1 a 2 a 3 a 4 a 5 a 6 a 7 a 8 a 9 a 10 a 11 ] = [ P ( x 0 ) P ( x 1 ) P ( x 2 ) P ( x 3 ) P ( x 4 ) P ( x 5 ) P ( x 6 ) P ( x 7 ) P ( x 8 ) P ( x 9 ) P ( x 10 ) P ( x 11 ) ] \begin{bmatrix}1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \\1 & \omega^1 & \omega^2 & \omega^3 & \omega^4 & \omega^5 & \omega^6 & \omega^7 & \omega^8 & \omega^9 & \omega^{10} & \omega^{11} \\1 & \omega^2 & \omega^4 & \omega^6 & \omega^8 & \omega^{10} & 1 & \omega^2 & \omega^4 & \omega^6 & \omega^8 & \omega^{10} \\1 & \omega^3 & \omega^6 & \omega^9 & 1 & \omega^3 & \omega^6 & \omega^9 & 1 & \omega^3 & \omega^6 & \omega^9 \\1 & \omega^4 & \omega^8 & 1 & \omega^4 & \omega^8 & 1 & \omega^4 & \omega^8 & 1 & \omega^4 & \omega^8 \\1 & \omega^5 & \omega^{10} & \omega^3 & \omega^8 & \omega^1 & \omega^6 & \omega^{11} & \omega^4 & \omega^9 & \omega^2 & \omega^7 \\1 & \omega^6 & 1 & \omega^6 & 1 & \omega^6 & 1 & \omega^6 & 1 & \omega^6 & 1 & \omega^6 \\1 & \omega^7 & \omega^2 & \omega^9 & \omega^4 & \omega^{11} & \omega^6 & \omega^1 & \omega^8 & \omega^3 & \omega^{10} & \omega^5 \\1 & \omega^8 & \omega^4 & 1 & \omega^8 & \omega^4 & 1 & \omega^8 & \omega^4 & 1 & \omega^8 & \omega^4 \\1 & \omega^9 & \omega^6 & \omega^3 & 1 & \omega^9 & \omega^6 & \omega^3 & 1 & \omega^9 & \omega^6 & \omega^3 \\1 & \omega^{10} & \omega^8 & \omega^6 & \omega^4 & \omega^2 & 1 & \omega^{10} & \omega^8 & \omega^6 & \omega^4 & \omega^2 \\1 & \omega^{11} & \omega^{10} & \omega^9 & \omega^8 & \omega^7 & \omega^6 & \omega^5 & \omega^4 & \omega^3 & \omega^2 & \omega^1 \\\end{bmatrix}\begin{bmatrix}
a_0 \\
a_1 \\
a_2 \\
a_3 \\
a_4 \\
a_5 \\
a_6 \\
a_7 \\
a_8 \\
a_9 \\
a_{10} \\
a_{11} \\
\end{bmatrix}
=
\begin{bmatrix}
P(x_0) \\
P(x_1) \\
P(x_2) \\
P(x_3) \\
P(x_4) \\
P(x_5) \\
P(x_6) \\
P(x_7) \\
P(x_8) \\
P(x_9) \\
P(x_{10}) \\
P(x_{11}) \\
\end{bmatrix} 1 1 1 1 1 1 1 1 1 1 1 1 1 ω 1 ω 2 ω 3 ω 4 ω 5 ω 6 ω 7 ω 8 ω 9 ω 10 ω 11 1 ω 2 ω 4 ω 6 ω 8 ω 10 1 ω 2 ω 4 ω 6 ω 8 ω 10 1 ω 3 ω 6 ω 9 1 ω 3 ω 6 ω 9 1 ω 3 ω 6 ω 9 1 ω 4 ω 8 1 ω 4 ω 8 1 ω 4 ω 8 1 ω 4 ω 8 1 ω 5 ω 10 ω 3 ω 8 ω 1 ω 6 ω 11 ω 4 ω 9 ω 2 ω 7 1 ω 6 1 ω 6 1 ω 6 1 ω 6 1 ω 6 1 ω 6 1 ω 7 ω 2 ω 9 ω 4 ω 11 ω 6 ω 1 ω 8 ω 3 ω 10 ω 5 1 ω 8 ω 4 1 ω 8 ω 4 1 ω 8 ω 4 1 ω 8 ω 4 1 ω 9 ω 6 ω 3 1 ω 9 ω 6 ω 3 1 ω 9 ω 6 ω 3 1 ω 10 ω 8 ω 6 ω 4 ω 2 1 ω 10 ω 8 ω 6 ω 4 ω 2 1 ω 11 ω 10 ω 9 ω 8 ω 7 ω 6 ω 5 ω 4 ω 3 ω 2 ω 1 a 0 a 1 a 2 a 3 a 4 a 5 a 6 a 7 a 8 a 9 a 10 a 11 = P ( x 0 ) P ( x 1 ) P ( x 2 ) P ( x 3 ) P ( x 4 ) P ( x 5 ) P ( x 6 ) P ( x 7 ) P ( x 8 ) P ( x 9 ) P ( x 10 ) P ( x 11 ) You’ll notice that a lot of terms seems to be repeated seemingly at random, this periodicity is what the Fast Fourier Transform takes advantage of.
Cooley-Tukey
There are a different FFT algorithms depending on the structure of the cyclic group that can be applied, but we’ll focus our attention on the most popular one, the Cooley-Tukey FFT[ 1 ] ^{[1]} [ 1 ] N = r 1 ⋅ r 2 N = r_1 \cdot r_2 N = r 1 ⋅ r 2
Then let
j = j 1 r 1 + j 0 , j 0 = 0 , 1 , … r 1 − 1 , j 1 = 0 , 1 , … r 2 − 1 k = k 1 r 1 + k 0 , k 0 = 0 , 1 , … r 2 − 1 , k 1 = 0 , 1 , … r 1 − 1 \begin{split}
j = j_1r_1 + j_0, \quad j_0 = 0,1,\dots r_1-1, \quad j_1 = 0,1,\dots r_2-1 \\
k = k_1r_1 + k_0, \quad k_0 = 0,1,\dots r_2-1, \quad k_1 = 0,1,\dots r_1-1
\end{split} j = j 1 r 1 + j 0 , j 0 = 0 , 1 , … r 1 − 1 , j 1 = 0 , 1 , … r 2 − 1 k = k 1 r 1 + k 0 , k 0 = 0 , 1 , … r 2 − 1 , k 1 = 0 , 1 , … r 1 − 1 Substituting the terms of j j j k k k ( 1 ) (1) ( 1 )
X ( j 1 r 1 + j 0 ) = ∑ k 1 r 2 + k 0 N − 1 A ( k 1 r 2 + k 0 ) ⋅ ω ( j 1 r 1 + j 0 ) ( k 1 r 2 + k 0 ) j 1 r 1 + j 0 = 0 , 1 , … N − 1. \begin{split}
X(j_1r_1 + j_0) = \sum^{N-1}_{k_1r_2+k_0}A(k_1r_2+k_0) \cdot \omega^{(j_1r_1+j_0)(k_1r_2+k_0)} \quad j_1r_1 + j_0 = 0,1,\dots N-1.
\end{split} X ( j 1 r 1 + j 0 ) = k 1 r 2 + k 0 ∑ N − 1 A ( k 1 r 2 + k 0 ) ⋅ ω ( j 1 r 1 + j 0 ) ( k 1 r 2 + k 0 ) j 1 r 1 + j 0 = 0 , 1 , … N − 1. Since r 1 r_1 r 1 r 2 r_2 r 2 X X X A A A
X ( j 1 , j 0 ) = ∑ k 0 = 0 r 2 − 1 ∑ k 1 = 0 r 1 − 1 A ( k 1 , k 0 ) ⋅ ω j 1 r 1 k 1 r 2 + j 1 r 1 k 0 + j 0 k 1 r 2 + j 0 k 0 = ∑ k 0 = 0 r 2 − 1 ∑ k 1 = 0 r 1 − 1 A ( k 1 , k 0 ) ⋅ ω j 1 r 1 k 1 r 2 ⋅ ω j 1 r 1 k 0 + j 0 k 1 r 2 + j 0 k 0 = ∑ k 0 = 0 r 2 − 1 ∑ k 1 = 0 r 1 − 1 A ( k 1 , k 0 ) ⋅ ( ω r 1 r 2 ) j 1 k 1 ⋅ ω j 1 r 1 k 0 + j 0 k 0 + j 0 k 1 r 2 = ∑ k 0 = 0 r 2 − 1 ∑ k 1 = 0 r 1 − 1 A ( k 1 , k 0 ) ⋅ ( ω N ) j 1 k 1 ⋅ ω ( j 1 r 1 + j 0 ) k 0 + j 0 k 1 r 2 = ∑ k 0 = 0 r 2 − 1 ∑ k 1 = 0 r 1 − 1 A ( k 1 , k 0 ) ⋅ ( 1 ) j 1 k 1 ⋅ ω j k 0 + j 0 k 1 r 2 = ∑ k 0 = 0 r 2 − 1 ∑ k 1 = 0 r 1 − 1 A ( k 1 , k 0 ) ⋅ ω j k 0 + j 0 k 1 r 2 \begin{split}
X(j_1,j_0) &= \sum^{r_2-1}_{k_0 = 0} \sum^{r_1-1}_{k_1 = 0} A(k_1, k_0) \cdot \omega^{j_1r_1k_1r_2 + j_1r_1k_0 + j_0k_1r_2+j_0k_0} \\
&= \sum^{r_2-1}_{k_0 = 0} \sum^{r_1-1}_{k_1 = 0} A(k_1, k_0) \cdot \omega^{j_1r_1k_1r_2}\cdot \omega^{j_1r_1k_0 + j_0k_1r_2+j_0k_0} \\
&= \sum^{r_2-1}_{k_0 = 0} \sum^{r_1-1}_{k_1 = 0} A(k_1, k_0) \cdot (\omega^{r_1r_2})^{j_1k_1}\cdot \omega^{j_1r_1k_0 +j_0k_0+ j_0k_1r_2}
\\
&= \sum^{r_2-1}_{k_0 = 0} \sum^{r_1-1}_{k_1 = 0} A(k_1, k_0) \cdot (\omega^{N})^{j_1k_1}\cdot \omega^{(j_1r_1 +j_0)k_0+ j_0k_1r_2}
\\
&= \sum^{r_2-1}_{k_0 = 0} \sum^{r_1-1}_{k_1 = 0} A(k_1, k_0) \cdot (1)^{j_1k_1}\cdot \omega^{jk_0+ j_0k_1r_2}
\\
&= \sum^{r_2-1}_{k_0 = 0} \sum^{r_1-1}_{k_1 = 0} A(k_1, k_0) \cdot \omega^{jk_0+ j_0k_1r_2}
\end{split} X ( j 1 , j 0 ) = k 0 = 0 ∑ r 2 − 1 k 1 = 0 ∑ r 1 − 1 A ( k 1 , k 0 ) ⋅ ω j 1 r 1 k 1 r 2 + j 1 r 1 k 0 + j 0 k 1 r 2 + j 0 k 0 = k 0 = 0 ∑ r 2 − 1 k 1 = 0 ∑ r 1 − 1 A ( k 1 , k 0 ) ⋅ ω j 1 r 1 k 1 r 2 ⋅ ω j 1 r 1 k 0 + j 0 k 1 r 2 + j 0 k 0 = k 0 = 0 ∑ r 2 − 1 k 1 = 0 ∑ r 1 − 1 A ( k 1 , k 0 ) ⋅ ( ω r 1 r 2 ) j 1 k 1 ⋅ ω j 1 r 1 k 0 + j 0 k 0 + j 0 k 1 r 2 = k 0 = 0 ∑ r 2 − 1 k 1 = 0 ∑ r 1 − 1 A ( k 1 , k 0 ) ⋅ ( ω N ) j 1 k 1 ⋅ ω ( j 1 r 1 + j 0 ) k 0 + j 0 k 1 r 2 = k 0 = 0 ∑ r 2 − 1 k 1 = 0 ∑ r 1 − 1 A ( k 1 , k 0 ) ⋅ ( 1 ) j 1 k 1 ⋅ ω j k 0 + j 0 k 1 r 2 = k 0 = 0 ∑ r 2 − 1 k 1 = 0 ∑ r 1 − 1 A ( k 1 , k 0 ) ⋅ ω j k 0 + j 0 k 1 r 2 Finally we obtain the equation
X ( j 1 , j 0 ) = ∑ k 0 = 0 r 2 − 1 ∑ k 1 = 0 r 1 − 1 A ( k 1 , k 0 ) ⋅ ω j k 0 ⋅ ω j 0 k 1 r 2 \begin{equation}
X(j_1, j_0) = \sum^{r_2-1}_{k_0 = 0} \sum^{r_1-1}_{k_1 = 0} A(k_1, k_0) \cdot \omega^{jk_0} \cdot \omega^{j_0k_1r_2} \tag{2}
\end{equation} X ( j 1 , j 0 ) = k 0 = 0 ∑ r 2 − 1 k 1 = 0 ∑ r 1 − 1 A ( k 1 , k 0 ) ⋅ ω j k 0 ⋅ ω j 0 k 1 r 2 ( 2 ) We can observe that the inner sum over k 1 k_1 k 1 j 0 j_0 j 0 k 0 k_0 k 0
A 1 ( j 0 , k 0 ) = ∑ k 1 = 0 r 1 − 1 A ( k 1 , k 0 ) ⋅ ( ω r 2 ) j 0 k 1 \begin{equation}
A_1(j_0, k_0) = \sum^{r_1-1}_{k_1 = 0} A(k_1, k_0) \cdot (\omega^{r_2})^{j_0k_1}\tag{3}
\end{equation} A 1 ( j 0 , k 0 ) = k 1 = 0 ∑ r 1 − 1 A ( k 1 , k 0 ) ⋅ ( ω r 2 ) j 0 k 1 ( 3 ) So that the DFT in ( 1 ) (1) ( 1 )
X ( j 1 , j 0 ) = ∑ k 0 = 0 r 2 − 1 A 1 ( j 0 , k 0 ) ⋅ ω ( j 1 r 1 + j 0 ) k 0 = ∑ k 0 = 0 r 2 − 1 A 1 ( j 0 , k 0 ) ⋅ ω j 0 k 0 ⋅ ( ω r 1 ) j 1 k 0 (4) \begin{split}
X(j_1, j_0) &= \sum^{r_2-1}_{k_0 = 0} A_1(j_0, k_0) \cdot \omega^{(j_1r_1+j_0)k_0} \\
&= \sum^{r_2-1}_{k_0 = 0} A_1(j_0, k_0) \cdot \omega^{j_0k_0} \cdot (\omega^{r_1})^{j_1k_0}
\tag{4} \\
\end{split} X ( j 1 , j 0 ) = k 0 = 0 ∑ r 2 − 1 A 1 ( j 0 , k 0 ) ⋅ ω ( j 1 r 1 + j 0 ) k 0 = k 0 = 0 ∑ r 2 − 1 A 1 ( j 0 , k 0 ) ⋅ ω j 0 k 0 ⋅ ( ω r 1 ) j 1 k 0 ( 4 ) Let’s work out an example DFT of size N = 12 N = 12 N = 12 r 1 = 4 r_1 = 4 r 1 = 4 r 2 = 3 r_2 = 3 r 2 = 3
A 1 ( 0 , 0 ) = A ( 0 , 0 ) ω 0 ⋅ 0 ⋅ 3 + A ( 1 , 0 ) ω 0 ⋅ 1 ⋅ 3 + A ( 2 , 0 ) ω 0 ⋅ 2 ⋅ 3 + A ( 3 , 0 ) ω 0 ⋅ 3 ⋅ 3 A 1 ( 0 , 1 ) = A ( 0 , 1 ) ω 0 ⋅ 0 ⋅ 3 + A ( 1 , 1 ) ω 0 ⋅ 1 ⋅ 3 + A ( 2 , 1 ) ω 0 ⋅ 2 ⋅ 3 + A ( 3 , 1 ) ω 0 ⋅ 3 ⋅ 3 A 1 ( 0 , 2 ) = A ( 0 , 2 ) ω 0 ⋅ 0 ⋅ 3 + A ( 1 , 2 ) ω 0 ⋅ 1 ⋅ 3 + A ( 2 , 2 ) ω 0 ⋅ 2 ⋅ 3 + A ( 3 , 2 ) ω 0 ⋅ 3 ⋅ 3 A 1 ( 1 , 0 ) = A ( 0 , 0 ) ω 1 ⋅ 0 ⋅ 3 + A ( 1 , 0 ) ω 1 ⋅ 1 ⋅ 3 + A ( 2 , 0 ) ω 1 ⋅ 2 ⋅ 3 + A ( 3 , 0 ) ω 1 ⋅ 3 ⋅ 3 A 1 ( 1 , 1 ) = A ( 0 , 1 ) ω 1 ⋅ 0 ⋅ 3 + A ( 1 , 1 ) ω 1 ⋅ 1 ⋅ 3 + A ( 2 , 1 ) ω 1 ⋅ 2 ⋅ 3 + A ( 3 , 1 ) ω 1 ⋅ 3 ⋅ 3 A 1 ( 1 , 2 ) = A ( 0 , 2 ) ω 1 ⋅ 0 ⋅ 3 + A ( 1 , 2 ) ω 1 ⋅ 1 ⋅ 3 + A ( 2 , 2 ) ω 1 ⋅ 2 ⋅ 3 + A ( 3 , 2 ) ω 1 ⋅ 3 ⋅ 3 A 1 ( 2 , 0 ) = A ( 0 , 0 ) ω 2 ⋅ 0 ⋅ 3 + A ( 1 , 0 ) ω 2 ⋅ 1 ⋅ 3 + A ( 2 , 0 ) ω 2 ⋅ 2 ⋅ 3 + A ( 3 , 0 ) ω 2 ⋅ 3 ⋅ 3 A 1 ( 2 , 1 ) = A ( 0 , 1 ) ω 2 ⋅ 0 ⋅ 3 + A ( 1 , 1 ) ω 2 ⋅ 1 ⋅ 3 + A ( 2 , 1 ) ω 2 ⋅ 2 ⋅ 3 + A ( 3 , 1 ) ω 2 ⋅ 3 ⋅ 3 A 1 ( 2 , 2 ) = A ( 0 , 2 ) ω 2 ⋅ 0 ⋅ 3 + A ( 1 , 2 ) ω 2 ⋅ 1 ⋅ 3 + A ( 2 , 2 ) ω 2 ⋅ 2 ⋅ 3 + A ( 3 , 2 ) ω 2 ⋅ 3 ⋅ 3 A 1 ( 3 , 0 ) = A ( 0 , 0 ) ω 3 ⋅ 0 ⋅ 3 + A ( 1 , 0 ) ω 3 ⋅ 1 ⋅ 3 + A ( 2 , 0 ) ω 3 ⋅ 2 ⋅ 3 + A ( 3 , 0 ) ω 3 ⋅ 3 ⋅ 3 A 1 ( 3 , 1 ) = A ( 0 , 1 ) ω 3 ⋅ 0 ⋅ 3 + A ( 1 , 1 ) ω 3 ⋅ 1 ⋅ 3 + A ( 2 , 1 ) ω 3 ⋅ 2 ⋅ 3 + A ( 3 , 1 ) ω 3 ⋅ 3 ⋅ 3 A 1 ( 3 , 2 ) = A ( 0 , 2 ) ω 3 ⋅ 0 ⋅ 3 + A ( 1 , 2 ) ω 3 ⋅ 1 ⋅ 3 + A ( 2 , 2 ) ω 3 ⋅ 2 ⋅ 3 + A ( 3 , 2 ) ω 3 ⋅ 3 ⋅ 3 \begin{aligned}A_1(0, 0) &= A(0, 0)\omega^{0\cdot0\cdot3} + A(1, 0)\omega^{0\cdot1\cdot3} + A(2, 0)\omega^{0\cdot2\cdot3} + A(3, 0)\omega^{0\cdot3\cdot3} \\A_1(0, 1) &= A(0, 1)\omega^{0\cdot0\cdot3} + A(1, 1)\omega^{0\cdot1\cdot3} + A(2, 1)\omega^{0\cdot2\cdot3} + A(3, 1)\omega^{0\cdot3\cdot3} \\A_1(0, 2) &= A(0, 2)\omega^{0\cdot0\cdot3} + A(1, 2)\omega^{0\cdot1\cdot3} + A(2, 2)\omega^{0\cdot2\cdot3} + A(3, 2)\omega^{0\cdot3\cdot3} \\ A_1(1, 0) &= A(0, 0)\omega^{1\cdot0\cdot3} + A(1, 0)\omega^{1\cdot1\cdot3} + A(2, 0)\omega^{1\cdot2\cdot3} + A(3, 0)\omega^{1\cdot3\cdot3} \\A_1(1, 1) &= A(0, 1)\omega^{1\cdot0\cdot3} + A(1, 1)\omega^{1\cdot1\cdot3} + A(2, 1)\omega^{1\cdot2\cdot3} + A(3, 1)\omega^{1\cdot3\cdot3} \\A_1(1, 2) &= A(0, 2)\omega^{1\cdot0\cdot3} + A(1, 2)\omega^{1\cdot1\cdot3} + A(2, 2)\omega^{1\cdot2\cdot3} + A(3, 2)\omega^{1\cdot3\cdot3} \\ A_1(2, 0) &= A(0, 0)\omega^{2\cdot0\cdot3} + A(1, 0)\omega^{2\cdot1\cdot3} + A(2, 0)\omega^{2\cdot2\cdot3} + A(3, 0)\omega^{2\cdot3\cdot3} \\A_1(2, 1) &= A(0, 1)\omega^{2\cdot0\cdot3} + A(1, 1)\omega^{2\cdot1\cdot3} + A(2, 1)\omega^{2\cdot2\cdot3} + A(3, 1)\omega^{2\cdot3\cdot3} \\A_1(2, 2) &= A(0, 2)\omega^{2\cdot0\cdot3} + A(1, 2)\omega^{2\cdot1\cdot3} + A(2, 2)\omega^{2\cdot2\cdot3} + A(3, 2)\omega^{2\cdot3\cdot3} \\A_1(3, 0) &= A(0, 0)\omega^{3\cdot0\cdot3} + A(1, 0)\omega^{3\cdot1\cdot3} + A(2, 0)\omega^{3\cdot2\cdot3} + A(3, 0)\omega^{3\cdot3\cdot3} \\ A_1(3, 1) &= A(0, 1)\omega^{3\cdot0\cdot3} + A(1, 1)\omega^{3\cdot1\cdot3} + A(2, 1)\omega^{3\cdot2\cdot3} + A(3, 1)\omega^{3\cdot3\cdot3} \\A_1(3, 2) &= A(0, 2)\omega^{3\cdot0\cdot3} + A(1, 2)\omega^{3\cdot1\cdot3} + A(2, 2)\omega^{3\cdot2\cdot3} + A(3, 2)\omega^{3\cdot3\cdot3} \\\end{aligned} A 1 ( 0 , 0 ) A 1 ( 0 , 1 ) A 1 ( 0 , 2 ) A 1 ( 1 , 0 ) A 1 ( 1 , 1 ) A 1 ( 1 , 2 ) A 1 ( 2 , 0 ) A 1 ( 2 , 1 ) A 1 ( 2 , 2 ) A 1 ( 3 , 0 ) A 1 ( 3 , 1 ) A 1 ( 3 , 2 ) = A ( 0 , 0 ) ω 0 ⋅ 0 ⋅ 3 + A ( 1 , 0 ) ω 0 ⋅ 1 ⋅ 3 + A ( 2 , 0 ) ω 0 ⋅ 2 ⋅ 3 + A ( 3 , 0 ) ω 0 ⋅ 3 ⋅ 3 = A ( 0 , 1 ) ω 0 ⋅ 0 ⋅ 3 + A ( 1 , 1 ) ω 0 ⋅ 1 ⋅ 3 + A ( 2 , 1 ) ω 0 ⋅ 2 ⋅ 3 + A ( 3 , 1 ) ω 0 ⋅ 3 ⋅ 3 = A ( 0 , 2 ) ω 0 ⋅ 0 ⋅ 3 + A ( 1 , 2 ) ω 0 ⋅ 1 ⋅ 3 + A ( 2 , 2 ) ω 0 ⋅ 2 ⋅ 3 + A ( 3 , 2 ) ω 0 ⋅ 3 ⋅ 3 = A ( 0 , 0 ) ω 1 ⋅ 0 ⋅ 3 + A ( 1 , 0 ) ω 1 ⋅ 1 ⋅ 3 + A ( 2 , 0 ) ω 1 ⋅ 2 ⋅ 3 + A ( 3 , 0 ) ω 1 ⋅ 3 ⋅ 3 = A ( 0 , 1 ) ω 1 ⋅ 0 ⋅ 3 + A ( 1 , 1 ) ω 1 ⋅ 1 ⋅ 3 + A ( 2 , 1 ) ω 1 ⋅ 2 ⋅ 3 + A ( 3 , 1 ) ω 1 ⋅ 3 ⋅ 3 = A ( 0 , 2 ) ω 1 ⋅ 0 ⋅ 3 + A ( 1 , 2 ) ω 1 ⋅ 1 ⋅ 3 + A ( 2 , 2 ) ω 1 ⋅ 2 ⋅ 3 + A ( 3 , 2 ) ω 1 ⋅ 3 ⋅ 3 = A ( 0 , 0 ) ω 2 ⋅ 0 ⋅ 3 + A ( 1 , 0 ) ω 2 ⋅ 1 ⋅ 3 + A ( 2 , 0 ) ω 2 ⋅ 2 ⋅ 3 + A ( 3 , 0 ) ω 2 ⋅ 3 ⋅ 3 = A ( 0 , 1 ) ω 2 ⋅ 0 ⋅ 3 + A ( 1 , 1 ) ω 2 ⋅ 1 ⋅ 3 + A ( 2 , 1 ) ω 2 ⋅ 2 ⋅ 3 + A ( 3 , 1 ) ω 2 ⋅ 3 ⋅ 3 = A ( 0 , 2 ) ω 2 ⋅ 0 ⋅ 3 + A ( 1 , 2 ) ω 2 ⋅ 1 ⋅ 3 + A ( 2 , 2 ) ω 2 ⋅ 2 ⋅ 3 + A ( 3 , 2 ) ω 2 ⋅ 3 ⋅ 3 = A ( 0 , 0 ) ω 3 ⋅ 0 ⋅ 3 + A ( 1 , 0 ) ω 3 ⋅ 1 ⋅ 3 + A ( 2 , 0 ) ω 3 ⋅ 2 ⋅ 3 + A ( 3 , 0 ) ω 3 ⋅ 3 ⋅ 3 = A ( 0 , 1 ) ω 3 ⋅ 0 ⋅ 3 + A ( 1 , 1 ) ω 3 ⋅ 1 ⋅ 3 + A ( 2 , 1 ) ω 3 ⋅ 2 ⋅ 3 + A ( 3 , 1 ) ω 3 ⋅ 3 ⋅ 3 = A ( 0 , 2 ) ω 3 ⋅ 0 ⋅ 3 + A ( 1 , 2 ) ω 3 ⋅ 1 ⋅ 3 + A ( 2 , 2 ) ω 3 ⋅ 2 ⋅ 3 + A ( 3 , 2 ) ω 3 ⋅ 3 ⋅ 3 Simplifying
A 1 ( 0 ) = A ( 0 ) ω 0 + A ( 3 ) ω 0 + A ( 6 ) ω 0 + A ( 9 ) ω 0 A 1 ( 1 ) = A ( 1 ) ω 0 + A ( 4 ) ω 0 + A ( 7 ) ω 0 + A ( 10 ) ω 0 A 1 ( 2 ) = A ( 2 ) ω 0 + A ( 5 ) ω 0 + A ( 8 ) ω 0 + A ( 11 ) ω 0 A 1 ( 3 ) = A ( 0 ) ω 0 + A ( 3 ) ω 3 + A ( 6 ) ω 6 + A ( 9 ) ω 9 A 1 ( 4 ) = A ( 1 ) ω 0 + A ( 4 ) ω 3 + A ( 7 ) ω 6 + A ( 10 ) ω 9 A 1 ( 5 ) = A ( 2 ) ω 0 + A ( 5 ) ω 3 + A ( 8 ) ω 6 + A ( 11 ) ω 9 A 1 ( 6 ) = A ( 0 ) ω 0 + A ( 3 ) ω 6 + A ( 6 ) ω 12 + A ( 9 ) ω 18 A 1 ( 7 ) = A ( 1 ) ω 0 + A ( 4 ) ω 6 + A ( 7 ) ω 12 + A ( 10 ) ω 18 A 1 ( 8 ) = A ( 2 ) ω 0 + A ( 5 ) ω 6 + A ( 8 ) ω 12 + A ( 11 ) ω 18 A 1 ( 9 ) = A ( 0 ) ω 0 + A ( 3 ) ω 9 + A ( 6 ) ω 18 + A ( 9 ) ω 27 A 1 ( 10 ) = A ( 1 ) ω 0 + A ( 4 ) ω 9 + A ( 7 ) ω 18 + A ( 10 ) ω 27 A 1 ( 11 ) = A ( 2 ) ω 0 + A ( 5 ) ω 9 + A ( 8 ) ω 18 + A ( 11 ) ω 27 \begin{aligned}A_1(0) &= A(0)\omega^{0} + A(3)\omega^{0} + A(6)\omega^{0} + A(9)\omega^{0} \\A_1(1) &= A(1)\omega^{0} + A(4)\omega^{0} + A(7)\omega^{0} + A(10)\omega^{0} \\A_1(2) &= A(2)\omega^{0} + A(5)\omega^{0} + A(8)\omega^{0} + A(11)\omega^{0} \\ A_1(3) &= A(0)\omega^{0} + A(3)\omega^{3} + A(6)\omega^{6} + A(9)\omega^{9} \\A_1(4) &= A(1)\omega^{0} + A(4)\omega^{3} + A(7)\omega^{6} + A(10)\omega^{9} \\A_1(5) &= A(2)\omega^{0} + A(5)\omega^{3} + A(8)\omega^{6} + A(11)\omega^{9} \\ A_1(6) &= A(0)\omega^{0} + A(3)\omega^{6} + A(6)\omega^{12} + A(9)\omega^{18} \\A_1(7) &= A(1)\omega^{0} + A(4)\omega^{6} + A(7)\omega^{12} + A(10)\omega^{18} \\A_1(8) &= A(2)\omega^{0} + A(5)\omega^{6} + A(8)\omega^{12} + A(11)\omega^{18} \\A_1(9) &= A(0)\omega^{0} + A(3)\omega^{9} + A(6)\omega^{18} + A(9)\omega^{27} \\ A_1(10) &= A(1)\omega^{0} + A(4)\omega^{9} + A(7)\omega^{18} + A(10)\omega^{27} \\A_1(11) &= A(2)\omega^{0} + A(5)\omega^{9} + A(8)\omega^{18} + A(11)\omega^{27} \\\end{aligned} A 1 ( 0 ) A 1 ( 1 ) A 1 ( 2 ) A 1 ( 3 ) A 1 ( 4 ) A 1 ( 5 ) A 1 ( 6 ) A 1 ( 7 ) A 1 ( 8 ) A 1 ( 9 ) A 1 ( 10 ) A 1 ( 11 ) = A ( 0 ) ω 0 + A ( 3 ) ω 0 + A ( 6 ) ω 0 + A ( 9 ) ω 0 = A ( 1 ) ω 0 + A ( 4 ) ω 0 + A ( 7 ) ω 0 + A ( 10 ) ω 0 = A ( 2 ) ω 0 + A ( 5 ) ω 0 + A ( 8 ) ω 0 + A ( 11 ) ω 0 = A ( 0 ) ω 0 + A ( 3 ) ω 3 + A ( 6 ) ω 6 + A ( 9 ) ω 9 = A ( 1 ) ω 0 + A ( 4 ) ω 3 + A ( 7 ) ω 6 + A ( 10 ) ω 9 = A ( 2 ) ω 0 + A ( 5 ) ω 3 + A ( 8 ) ω 6 + A ( 11 ) ω 9 = A ( 0 ) ω 0 + A ( 3 ) ω 6 + A ( 6 ) ω 12 + A ( 9 ) ω 18 = A ( 1 ) ω 0 + A ( 4 ) ω 6 + A ( 7 ) ω 12 + A ( 10 ) ω 18 = A ( 2 ) ω 0 + A ( 5 ) ω 6 + A ( 8 ) ω 12 + A ( 11 ) ω 18 = A ( 0 ) ω 0 + A ( 3 ) ω 9 + A ( 6 ) ω 18 + A ( 9 ) ω 27 = A ( 1 ) ω 0 + A ( 4 ) ω 9 + A ( 7 ) ω 18 + A ( 10 ) ω 27 = A ( 2 ) ω 0 + A ( 5 ) ω 9 + A ( 8 ) ω 18 + A ( 11 ) ω 27 The keen eye will recognise that since A ( k 1 , k 0 ) A(k_1, k_0) A ( k 1 , k 0 ) A 1 ( j 0 , k 0 ) A_1(j_0, k_0) A 1 ( j 0 , k 0 )
[ ω 0 ω 0 ω 0 ω 0 ω 0 ω 3 ω 6 ω 9 ω 0 ω 6 ω 12 ω 18 ω 0 ω 9 ω 18 ω 27 ] ⏟ ( ω r 2 ) j 0 k 1 [ A ( 0 ) A ( 1 ) A ( 2 ) A ( 3 ) A ( 4 ) A ( 5 ) A ( 6 ) A ( 7 ) A ( 8 ) A ( 9 ) A ( 10 ) A ( 11 ) ] ⏟ A ( k 1 , k 0 ) = [ A 1 ( 0 , 0 ) A 1 ( 0 , 1 ) A 1 ( 0 , 2 ) A 1 ( 1 , 0 ) A 1 ( 1 , 1 ) A 1 ( 1 , 2 ) A 1 ( 2 , 0 ) A 1 ( 2 , 1 ) A 1 ( 2 , 3 ) A 1 ( 3 , 0 ) A 1 ( 3 , 1 ) A 1 ( 3 , 2 ) ] ⏟ A 1 ( j 0 , k 0 ) \underbrace{\begin{bmatrix}\omega^0 & \omega^0 & \omega^0 & \omega^0 \\\omega^0 & \omega^3 & \omega^6 & \omega^9 \\\omega^0 & \omega^6 & \omega^{12} & \omega^{18} \\\omega^0 & \omega^9 & \omega^{18} & \omega^{27} \\\end{bmatrix}}_{(\omega^{r_2})^{j_0k_1}}
\underbrace{\begin{bmatrix}
A(0) & A(1) & A(2)\\ A(3) & A(4) & A(5)\\ A(6) & A(7) & A(8)\\ A(9) & A(10) & A( 11)\\\end{bmatrix}}_{A(k_1, k_0)} = \underbrace{\begin{bmatrix}A_1(0, 0) & A_1(0, 1) & A_1(0, 2) \\A_1(1, 0) & A_1(1, 1) & A_1(1, 2) \\A_1(2, 0) & A_1(2, 1) & A_1(2, 3) \\A_1(3, 0) & A_1(3, 1) & A_1(3, 2) \\\end{bmatrix}}_{A_1(j_0, k_0)} ( ω r 2 ) j 0 k 1 ω 0 ω 0 ω 0 ω 0 ω 0 ω 3 ω 6 ω 9 ω 0 ω 6 ω 12 ω 18 ω 0 ω 9 ω 18 ω 27 A ( k 1 , k 0 ) A ( 0 ) A ( 3 ) A ( 6 ) A ( 9 ) A ( 1 ) A ( 4 ) A ( 7 ) A ( 10 ) A ( 2 ) A ( 5 ) A ( 8 ) A ( 11 ) = A 1 ( j 0 , k 0 ) A 1 ( 0 , 0 ) A 1 ( 1 , 0 ) A 1 ( 2 , 0 ) A 1 ( 3 , 0 ) A 1 ( 0 , 1 ) A 1 ( 1 , 1 ) A 1 ( 2 , 1 ) A 1 ( 3 , 1 ) A 1 ( 0 , 2 ) A 1 ( 1 , 2 ) A 1 ( 2 , 3 ) A 1 ( 3 , 2 ) Next we write out the terms for X ( j 1 , j 0 ) X(j_1, j_0) X ( j 1 , j 0 )
X ( 0 , 0 ) = A 1 ( 0 , 0 ) ω 4 ⋅ 0 ⋅ 0 ⋅ w 0 ⋅ 0 + A 1 ( 0 , 1 ) ω 4 ⋅ 0 ⋅ 1 ⋅ w 0 ⋅ 1 + A 1 ( 0 , 2 ) ω 4 ⋅ 0 ⋅ 2 ⋅ w 0 ⋅ 2 X ( 0 , 1 ) = A 1 ( 1 , 0 ) ω 4 ⋅ 0 ⋅ 0 ⋅ w 1 ⋅ 0 + A 1 ( 1 , 1 ) ω 4 ⋅ 0 ⋅ 1 ⋅ w 1 ⋅ 1 + A 1 ( 1 , 2 ) ω 4 ⋅ 0 ⋅ 2 ⋅ w 1 ⋅ 2 X ( 0 , 2 ) = A 1 ( 2 , 0 ) ω 4 ⋅ 0 ⋅ 0 ⋅ w 2 ⋅ 0 + A 1 ( 2 , 1 ) ω 4 ⋅ 0 ⋅ 1 ⋅ w 2 ⋅ 1 + A 1 ( 2 , 2 ) ω 4 ⋅ 0 ⋅ 2 ⋅ w 2 ⋅ 2 X ( 0 , 3 ) = A 1 ( 3 , 0 ) ω 4 ⋅ 0 ⋅ 0 ⋅ w 3 ⋅ 0 + A 1 ( 3 , 1 ) ω 4 ⋅ 0 ⋅ 1 ⋅ w 3 ⋅ 1 + A 1 ( 3 , 2 ) ω 4 ⋅ 0 ⋅ 2 ⋅ w 3 ⋅ 2 X ( 1 , 0 ) = A 1 ( 0 , 0 ) ω 4 ⋅ 1 ⋅ 0 ⋅ w 0 ⋅ 0 + A 1 ( 0 , 1 ) ω 4 ⋅ 1 ⋅ 1 ⋅ w 0 ⋅ 1 + A 1 ( 0 , 2 ) ω 4 ⋅ 1 ⋅ 2 ⋅ w 0 ⋅ 2 X ( 1 , 1 ) = A 1 ( 1 , 0 ) ω 4 ⋅ 1 ⋅ 0 ⋅ w 1 ⋅ 0 + A 1 ( 1 , 1 ) ω 4 ⋅ 1 ⋅ 1 ⋅ w 1 ⋅ 1 + A 1 ( 1 , 2 ) ω 4 ⋅ 1 ⋅ 2 ⋅ w 1 ⋅ 2 X ( 1 , 2 ) = A 1 ( 2 , 0 ) ω 4 ⋅ 1 ⋅ 0 ⋅ w 2 ⋅ 0 + A 1 ( 2 , 1 ) ω 4 ⋅ 1 ⋅ 1 ⋅ w 2 ⋅ 1 + A 1 ( 2 , 2 ) ω 4 ⋅ 1 ⋅ 2 ⋅ w 2 ⋅ 2 X ( 1 , 3 ) = A 1 ( 3 , 0 ) ω 4 ⋅ 1 ⋅ 0 ⋅ w 3 ⋅ 0 + A 1 ( 3 , 1 ) ω 4 ⋅ 1 ⋅ 1 ⋅ w 3 ⋅ 1 + A 1 ( 3 , 2 ) ω 4 ⋅ 1 ⋅ 2 ⋅ w 3 ⋅ 2 X ( 2 , 0 ) = A 1 ( 0 , 0 ) ω 4 ⋅ 2 ⋅ 0 ⋅ w 0 ⋅ 0 + A 1 ( 0 , 1 ) ω 4 ⋅ 2 ⋅ 1 ⋅ w 0 ⋅ 1 + A 1 ( 0 , 2 ) ω 4 ⋅ 2 ⋅ 2 ⋅ w 0 ⋅ 2 X ( 2 , 1 ) = A 1 ( 1 , 0 ) ω 4 ⋅ 2 ⋅ 0 ⋅ w 1 ⋅ 0 + A 1 ( 1 , 1 ) ω 4 ⋅ 2 ⋅ 1 ⋅ w 1 ⋅ 1 + A 1 ( 1 , 2 ) ω 4 ⋅ 2 ⋅ 2 ⋅ w 1 ⋅ 2 X ( 2 , 2 ) = A 1 ( 2 , 0 ) ω 4 ⋅ 2 ⋅ 0 ⋅ w 2 ⋅ 0 + A 1 ( 2 , 1 ) ω 4 ⋅ 2 ⋅ 1 ⋅ w 2 ⋅ 1 + A 1 ( 2 , 2 ) ω 4 ⋅ 2 ⋅ 2 ⋅ w 2 ⋅ 2 X ( 2 , 3 ) = A 1 ( 3 , 0 ) ω 4 ⋅ 2 ⋅ 0 ⋅ w 3 ⋅ 0 + A 1 ( 3 , 1 ) ω 4 ⋅ 2 ⋅ 1 ⋅ w 3 ⋅ 1 + A 1 ( 3 , 2 ) ω 4 ⋅ 2 ⋅ 2 ⋅ w 3 ⋅ 2 \begin{aligned}X(0, 0) &= A_1(0, 0) \omega^{4\cdot0\cdot0} \cdot w^{0\cdot0} + A_1(0, 1) \omega^{4\cdot0\cdot1} \cdot w^{0\cdot1} + A_1(0, 2) \omega^{4\cdot0\cdot2} \cdot w^{0\cdot2} \\X(0, 1) &= A_1(1, 0) \omega^{4\cdot0\cdot0} \cdot w^{1\cdot0} + A_1(1, 1) \omega^{4\cdot0\cdot1} \cdot w^{1\cdot1} + A_1(1, 2) \omega^{4\cdot0\cdot2} \cdot w^{1\cdot2} \\X(0, 2) &= A_1(2, 0) \omega^{4\cdot0\cdot0} \cdot w^{2\cdot0} + A_1(2, 1) \omega^{4\cdot0\cdot1} \cdot w^{2\cdot1} + A_1(2, 2) \omega^{4\cdot0\cdot2} \cdot w^{2\cdot2} \\X(0, 3) &= A_1(3, 0) \omega^{4\cdot0\cdot0} \cdot w^{3\cdot0} + A_1(3, 1) \omega^{4\cdot0\cdot1} \cdot w^{3\cdot1} + A_1(3, 2) \omega^{4\cdot0\cdot2} \cdot w^{3\cdot2} \\X(1, 0) &= A_1(0, 0) \omega^{4\cdot1\cdot0} \cdot w^{0\cdot0} + A_1(0, 1) \omega^{4\cdot1\cdot1} \cdot w^{0\cdot1} + A_1(0, 2) \omega^{4\cdot1\cdot2} \cdot w^{0\cdot2} \\X(1, 1) &= A_1(1, 0) \omega^{4\cdot1\cdot0} \cdot w^{1\cdot0} + A_1(1, 1) \omega^{4\cdot1\cdot1} \cdot w^{1\cdot1} + A_1(1, 2) \omega^{4\cdot1\cdot2} \cdot w^{1\cdot2} \\X(1, 2) &= A_1(2, 0) \omega^{4\cdot1\cdot0} \cdot w^{2\cdot0} + A_1(2, 1) \omega^{4\cdot1\cdot1} \cdot w^{2\cdot1} + A_1(2, 2) \omega^{4\cdot1\cdot2} \cdot w^{2\cdot2} \\X(1, 3) &= A_1(3, 0) \omega^{4\cdot1\cdot0} \cdot w^{3\cdot0} + A_1(3, 1) \omega^{4\cdot1\cdot1} \cdot w^{3\cdot1} + A_1(3, 2) \omega^{4\cdot1\cdot2} \cdot w^{3\cdot2} \\X(2, 0) &= A_1(0, 0) \omega^{4\cdot2\cdot0} \cdot w^{0\cdot0} + A_1(0, 1) \omega^{4\cdot2\cdot1} \cdot w^{0\cdot1} + A_1(0, 2) \omega^{4\cdot2\cdot2} \cdot w^{0\cdot2} \\X(2, 1) &= A_1(1, 0) \omega^{4\cdot2\cdot0} \cdot w^{1\cdot0} + A_1(1, 1) \omega^{4\cdot2\cdot1} \cdot w^{1\cdot1} + A_1(1, 2) \omega^{4\cdot2\cdot2} \cdot w^{1\cdot2} \\X(2, 2) &= A_1(2, 0) \omega^{4\cdot2\cdot0} \cdot w^{2\cdot0} + A_1(2, 1) \omega^{4\cdot2\cdot1} \cdot w^{2\cdot1} + A_1(2, 2) \omega^{4\cdot2\cdot2} \cdot w^{2\cdot2} \\X(2, 3) &= A_1(3, 0) \omega^{4\cdot2\cdot0} \cdot w^{3\cdot0} + A_1(3, 1) \omega^{4\cdot2\cdot1} \cdot w^{3\cdot1} + A_1(3, 2) \omega^{4\cdot2\cdot2} \cdot w^{3\cdot2} \\\end{aligned} X ( 0 , 0 ) X ( 0 , 1 ) X ( 0 , 2 ) X ( 0 , 3 ) X ( 1 , 0 ) X ( 1 , 1 ) X ( 1 , 2 ) X ( 1 , 3 ) X ( 2 , 0 ) X ( 2 , 1 ) X ( 2 , 2 ) X ( 2 , 3 ) = A 1 ( 0 , 0 ) ω 4 ⋅ 0 ⋅ 0 ⋅ w 0 ⋅ 0 + A 1 ( 0 , 1 ) ω 4 ⋅ 0 ⋅ 1 ⋅ w 0 ⋅ 1 + A 1 ( 0 , 2 ) ω 4 ⋅ 0 ⋅ 2 ⋅ w 0 ⋅ 2 = A 1 ( 1 , 0 ) ω 4 ⋅ 0 ⋅ 0 ⋅ w 1 ⋅ 0 + A 1 ( 1 , 1 ) ω 4 ⋅ 0 ⋅ 1 ⋅ w 1 ⋅ 1 + A 1 ( 1 , 2 ) ω 4 ⋅ 0 ⋅ 2 ⋅ w 1 ⋅ 2 = A 1 ( 2 , 0 ) ω 4 ⋅ 0 ⋅ 0 ⋅ w 2 ⋅ 0 + A 1 ( 2 , 1 ) ω 4 ⋅ 0 ⋅ 1 ⋅ w 2 ⋅ 1 + A 1 ( 2 , 2 ) ω 4 ⋅ 0 ⋅ 2 ⋅ w 2 ⋅ 2 = A 1 ( 3 , 0 ) ω 4 ⋅ 0 ⋅ 0 ⋅ w 3 ⋅ 0 + A 1 ( 3 , 1 ) ω 4 ⋅ 0 ⋅ 1 ⋅ w 3 ⋅ 1 + A 1 ( 3 , 2 ) ω 4 ⋅ 0 ⋅ 2 ⋅ w 3 ⋅ 2 = A 1 ( 0 , 0 ) ω 4 ⋅ 1 ⋅ 0 ⋅ w 0 ⋅ 0 + A 1 ( 0 , 1 ) ω 4 ⋅ 1 ⋅ 1 ⋅ w 0 ⋅ 1 + A 1 ( 0 , 2 ) ω 4 ⋅ 1 ⋅ 2 ⋅ w 0 ⋅ 2 = A 1 ( 1 , 0 ) ω 4 ⋅ 1 ⋅ 0 ⋅ w 1 ⋅ 0 + A 1 ( 1 , 1 ) ω 4 ⋅ 1 ⋅ 1 ⋅ w 1 ⋅ 1 + A 1 ( 1 , 2 ) ω 4 ⋅ 1 ⋅ 2 ⋅ w 1 ⋅ 2 = A 1 ( 2 , 0 ) ω 4 ⋅ 1 ⋅ 0 ⋅ w 2 ⋅ 0 + A 1 ( 2 , 1 ) ω 4 ⋅ 1 ⋅ 1 ⋅ w 2 ⋅ 1 + A 1 ( 2 , 2 ) ω 4 ⋅ 1 ⋅ 2 ⋅ w 2 ⋅ 2 = A 1 ( 3 , 0 ) ω 4 ⋅ 1 ⋅ 0 ⋅ w 3 ⋅ 0 + A 1 ( 3 , 1 ) ω 4 ⋅ 1 ⋅ 1 ⋅ w 3 ⋅ 1 + A 1 ( 3 , 2 ) ω 4 ⋅ 1 ⋅ 2 ⋅ w 3 ⋅ 2 = A 1 ( 0 , 0 ) ω 4 ⋅ 2 ⋅ 0 ⋅ w 0 ⋅ 0 + A 1 ( 0 , 1 ) ω 4 ⋅ 2 ⋅ 1 ⋅ w 0 ⋅ 1 + A 1 ( 0 , 2 ) ω 4 ⋅ 2 ⋅ 2 ⋅ w 0 ⋅ 2 = A 1 ( 1 , 0 ) ω 4 ⋅ 2 ⋅ 0 ⋅ w 1 ⋅ 0 + A 1 ( 1 , 1 ) ω 4 ⋅ 2 ⋅ 1 ⋅ w 1 ⋅ 1 + A 1 ( 1 , 2 ) ω 4 ⋅ 2 ⋅ 2 ⋅ w 1 ⋅ 2 = A 1 ( 2 , 0 ) ω 4 ⋅ 2 ⋅ 0 ⋅ w 2 ⋅ 0 + A 1 ( 2 , 1 ) ω 4 ⋅ 2 ⋅ 1 ⋅ w 2 ⋅ 1 + A 1 ( 2 , 2 ) ω 4 ⋅ 2 ⋅ 2 ⋅ w 2 ⋅ 2 = A 1 ( 3 , 0 ) ω 4 ⋅ 2 ⋅ 0 ⋅ w 3 ⋅ 0 + A 1 ( 3 , 1 ) ω 4 ⋅ 2 ⋅ 1 ⋅ w 3 ⋅ 1 + A 1 ( 3 , 2 ) ω 4 ⋅ 2 ⋅ 2 ⋅ w 3 ⋅ 2 Simplifying, we get
X ( 0 ) = A 1 ( 0 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 1 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 2 ) ⋅ ω 0 ⋅ w 0 X ( 1 ) = A 1 ( 3 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 4 ) ⋅ ω 0 ⋅ w 1 + A 1 ( 5 ) ⋅ ω 0 ⋅ w 2 X ( 2 ) = A 1 ( 6 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 7 ) ⋅ ω 0 ⋅ w 2 + A 1 ( 8 ) ⋅ ω 0 ⋅ w 4 X ( 3 ) = A 1 ( 9 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 10 ) ⋅ ω 0 ⋅ w 3 + A 1 ( 11 ) ⋅ ω 0 ⋅ w 6 X ( 4 ) = A 1 ( 0 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 1 ) ⋅ ω 4 ⋅ w 0 + A 1 ( 2 ) ⋅ ω 8 ⋅ w 0 X ( 5 ) = A 1 ( 3 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 4 ) ⋅ ω 4 ⋅ w 1 + A 1 ( 5 ) ⋅ ω 8 ⋅ w 2 X ( 6 ) = A 1 ( 6 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 7 ) ⋅ ω 4 ⋅ w 2 + A 1 ( 8 ) ⋅ ω 8 ⋅ w 4 X ( 7 ) = A 1 ( 9 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 10 ) ⋅ ω 4 ⋅ w 3 + A 1 ( 11 ) ⋅ ω 8 ⋅ w 6 X ( 8 ) = A 1 ( 0 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 1 ) ⋅ ω 8 ⋅ w 0 + A 1 ( 2 ) ⋅ ω 16 ⋅ w 0 X ( 9 ) = A 1 ( 3 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 4 ) ⋅ ω 8 ⋅ w 1 + A 1 ( 5 ) ⋅ ω 16 ⋅ w 2 X ( 10 ) = A 1 ( 6 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 7 ) ⋅ ω 8 ⋅ w 2 + A 1 ( 8 ) ⋅ ω 16 ⋅ w 4 X ( 11 ) = A 1 ( 9 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 10 ) ⋅ ω 8 ⋅ w 3 + A 1 ( 11 ) ⋅ ω 16 ⋅ w 6 \begin{aligned}X(0) &= A_1(0) \cdot \omega^{0} \cdot w^{0} + A_1(1) \cdot \omega^{0} \cdot w^{0} + A_1(2) \cdot \omega^{0} \cdot w^{0} \\X(1) &= A_1(3) \cdot \omega^{0} \cdot w^{0} + A_1(4) \cdot \omega^{0} \cdot w^{1} + A_1(5) \cdot \omega^{0} \cdot w^{2} \\X(2) &= A_1(6) \cdot \omega^{0} \cdot w^{0} + A_1(7) \cdot \omega^{0} \cdot w^{2} + A_1(8) \cdot \omega^{0} \cdot w^{4} \\X(3) &= A_1(9) \cdot \omega^{0} \cdot w^{0} + A_1(10) \cdot \omega^{0} \cdot w^{3} + A_1(11) \cdot \omega^{0} \cdot w^{6} \\X(4) &= A_1(0) \cdot \omega^{0} \cdot w^{0} + A_1(1) \cdot \omega^{4} \cdot w^{0} + A_1(2) \cdot \omega^{8} \cdot w^{0} \\X(5) &= A_1(3) \cdot \omega^{0} \cdot w^{0} + A_1(4) \cdot \omega^{4} \cdot w^{1} + A_1(5) \cdot \omega^{8} \cdot w^{2} \\X(6) &= A_1(6) \cdot \omega^{0} \cdot w^{0} + A_1(7) \cdot \omega^{4} \cdot w^{2} + A_1(8) \cdot \omega^{8} \cdot w^{4} \\X(7) &= A_1(9) \cdot \omega^{0} \cdot w^{0} + A_1(10) \cdot \omega^{4} \cdot w^{3} + A_1(11) \cdot \omega^{8} \cdot w^{6} \\X(8) &= A_1(0) \cdot \omega^{0} \cdot w^{0} + A_1(1) \cdot \omega^{8} \cdot w^{0} + A_1(2) \cdot \omega^{16} \cdot w^{0} \\X(9) &= A_1(3) \cdot \omega^{0} \cdot w^{0} + A_1(4) \cdot \omega^{8} \cdot w^{1} + A_1(5) \cdot \omega^{16} \cdot w^{2} \\X(10) &= A_1(6) \cdot \omega^{0} \cdot w^{0} + A_1(7) \cdot \omega^{8} \cdot w^{2} + A_1(8) \cdot \omega^{16} \cdot w^{4} \\X(11) &= A_1(9) \cdot \omega^{0} \cdot w^{0} + A_1(10) \cdot \omega^{8} \cdot w^{3} + A_1(11) \cdot \omega^{16} \cdot w^{6} \\\end{aligned} X ( 0 ) X ( 1 ) X ( 2 ) X ( 3 ) X ( 4 ) X ( 5 ) X ( 6 ) X ( 7 ) X ( 8 ) X ( 9 ) X ( 10 ) X ( 11 ) = A 1 ( 0 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 1 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 2 ) ⋅ ω 0 ⋅ w 0 = A 1 ( 3 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 4 ) ⋅ ω 0 ⋅ w 1 + A 1 ( 5 ) ⋅ ω 0 ⋅ w 2 = A 1 ( 6 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 7 ) ⋅ ω 0 ⋅ w 2 + A 1 ( 8 ) ⋅ ω 0 ⋅ w 4 = A 1 ( 9 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 10 ) ⋅ ω 0 ⋅ w 3 + A 1 ( 11 ) ⋅ ω 0 ⋅ w 6 = A 1 ( 0 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 1 ) ⋅ ω 4 ⋅ w 0 + A 1 ( 2 ) ⋅ ω 8 ⋅ w 0 = A 1 ( 3 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 4 ) ⋅ ω 4 ⋅ w 1 + A 1 ( 5 ) ⋅ ω 8 ⋅ w 2 = A 1 ( 6 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 7 ) ⋅ ω 4 ⋅ w 2 + A 1 ( 8 ) ⋅ ω 8 ⋅ w 4 = A 1 ( 9 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 10 ) ⋅ ω 4 ⋅ w 3 + A 1 ( 11 ) ⋅ ω 8 ⋅ w 6 = A 1 ( 0 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 1 ) ⋅ ω 8 ⋅ w 0 + A 1 ( 2 ) ⋅ ω 16 ⋅ w 0 = A 1 ( 3 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 4 ) ⋅ ω 8 ⋅ w 1 + A 1 ( 5 ) ⋅ ω 16 ⋅ w 2 = A 1 ( 6 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 7 ) ⋅ ω 8 ⋅ w 2 + A 1 ( 8 ) ⋅ ω 16 ⋅ w 4 = A 1 ( 9 ) ⋅ ω 0 ⋅ w 0 + A 1 ( 10 ) ⋅ ω 8 ⋅ w 3 + A 1 ( 11 ) ⋅ ω 16 ⋅ w 6 Visualising the above eqs in matrix form is a bit tricky, because we seem to be multiplying 3 matrices here. But upon closer inspection, two of them is an element-wise product or so-called Hadamard product
A ⋅ B = A i j ⋅ B i j A \cdot B = A_{ij} \cdot B_{ij} A ⋅ B = A ij ⋅ B ij Revisiting eq ( 4 ) (4) ( 4 )
X ( j 1 , j 0 ) = ∑ k 0 = 0 r 2 − 1 A 1 ( j 0 , k 0 ) ⋅ ω j 0 k 0 ⏟ hadamard product ⋅ ( ω r 1 ) j 1 k 0 = ∑ k 0 = 0 r 2 − 1 ( A 1 ( j 0 , k 0 ) ω j 0 k 0 ) ⋅ ( ω r 1 ) j 1 k 0 \begin{split}
X(j_1, j_0) &= \sum^{r_2-1}_{k_0 = 0} \underbrace{A_1(j_0, k_0) \cdot \omega^{j_0k_0}}_{\text{hadamard product}} \cdot (\omega^{r_1})^{j_1k_0} \\
&= \sum^{r_2-1}_{k_0 = 0} (A_1(j_0, k_0)\omega^{j_0k_0}) \cdot (\omega^{r_1})^{j_1k_0}
\end{split} X ( j 1 , j 0 ) = k 0 = 0 ∑ r 2 − 1 hadamard product A 1 ( j 0 , k 0 ) ⋅ ω j 0 k 0 ⋅ ( ω r 1 ) j 1 k 0 = k 0 = 0 ∑ r 2 − 1 ( A 1 ( j 0 , k 0 ) ω j 0 k 0 ) ⋅ ( ω r 1 ) j 1 k 0 The matrix ω j 0 k 0 \omega^{j_0k_0} ω j 0 k 0
[ A 1 ( 0 ) A 1 ( 1 ) A 1 ( 2 ) A 1 ( 3 ) A 1 ( 4 ) A 1 ( 5 ) A 1 ( 6 ) A 1 ( 7 ) A 1 ( 8 ) A 1 ( 9 ) A 1 ( 10 ) A 1 ( 11 ) ] ⏟ A 1 ( j 0 , k 0 ) [ ω 0 ω 0 ω 0 ω 0 ω 1 ω 2 ω 0 ω 2 ω 4 ω 0 ω 3 ω 6 ] ⏟ ω j 0 k 0 = [ A 1 ( 0 , 0 ) ⋅ ω 0 A 1 ( 0 , 1 ) ⋅ ω 0 A 1 ( 0 , 2 ) ⋅ ω 0 A 1 ( 1 , 0 ) ⋅ ω 0 A 1 ( 1 , 1 ) ⋅ ω 1 A 1 ( 1 , 2 ) ⋅ ω 2 A 1 ( 2 , 0 ) ⋅ ω 0 A 1 ( 2 , 1 ) ⋅ ω 2 A 1 ( 2 , 2 ) ⋅ ω 4 A 1 ( 3 , 0 ) ⋅ ω 0 A 1 ( 3 , 1 ) ⋅ ω 3 A 1 ( 3 , 2 ) ⋅ ω 6 ] ⏟ A 1 ( j 0 , k 0 ) ⋅ ω j 0 k 0 \underbrace{\begin{bmatrix}A_1(0) & A_1(1) & A_1(2) \\A_1(3) & A_1(4) & A_1(5) \\A_1(6) & A_1(7) & A_1(8) \\A_1(9) & A_1(10) & A_1(11) \\\end{bmatrix}}_{A_1(j_0, k_0)}
\underbrace{\begin{bmatrix} \omega^0 &\omega^0 & \omega^0 \\ \omega^0 & \omega^1 & \omega^2 \\ \omega^0 & \omega^2 & \omega^4 \\ \omega^0 & \omega^3 & \omega^6 \\
\end{bmatrix}}_{\omega^{j_0k_0}}
=
\underbrace{\begin{bmatrix}A_1(0, 0) \cdot \omega^0 & A_1(0, 1) \cdot \omega^0 & A_1(0, 2) \cdot \omega^0 \\A_1(1, 0) \cdot \omega^0 & A_1(1, 1) \cdot \omega^1 & A_1(1, 2) \cdot \omega^2 \\A_1(2, 0) \cdot \omega^0 & A_1(2, 1) \cdot \omega^2 & A_1(2, 2) \cdot \omega^4 \\A_1(3, 0) \cdot \omega^0 & A_1(3, 1) \cdot \omega^3 & A_1(3, 2) \cdot \omega^6 \\\end{bmatrix}}_{A_1(j_0, k_0) \cdot \omega^{j_0k_0}} A 1 ( j 0 , k 0 ) A 1 ( 0 ) A 1 ( 3 ) A 1 ( 6 ) A 1 ( 9 ) A 1 ( 1 ) A 1 ( 4 ) A 1 ( 7 ) A 1 ( 10 ) A 1 ( 2 ) A 1 ( 5 ) A 1 ( 8 ) A 1 ( 11 ) ω j 0 k 0 ω 0 ω 0 ω 0 ω 0 ω 0 ω 1 ω 2 ω 3 ω 0 ω 2 ω 4 ω 6 = A 1 ( j 0 , k 0 ) ⋅ ω j 0 k 0 A 1 ( 0 , 0 ) ⋅ ω 0 A 1 ( 1 , 0 ) ⋅ ω 0 A 1 ( 2 , 0 ) ⋅ ω 0 A 1 ( 3 , 0 ) ⋅ ω 0 A 1 ( 0 , 1 ) ⋅ ω 0 A 1 ( 1 , 1 ) ⋅ ω 1 A 1 ( 2 , 1 ) ⋅ ω 2 A 1 ( 3 , 1 ) ⋅ ω 3 A 1 ( 0 , 2 ) ⋅ ω 0 A 1 ( 1 , 2 ) ⋅ ω 2 A 1 ( 2 , 2 ) ⋅ ω 4 A 1 ( 3 , 2 ) ⋅ ω 6 Now it’s finally time to multiply by our ( ω r 1 ) j 1 k 0 (\omega^{r_1})^{j_1k_0} ( ω r 1 ) j 1 k 0 X ( j 1 , j 0 ) X(j_1, j_0) X ( j 1 , j 0 ) transposed matrix , given as:
A j i ′ = A i j A^\prime_{ji} = A_{ij} A j i ′ = A ij Therefore we take the transpose of the result of this element-wise multiplication so that the multiplication is in the correct column-order.
[ A 1 ( 0 , 0 ) ⋅ ω 0 A 1 ( 1 , 0 ) ⋅ ω 0 A 1 ( 2 , 0 ) ⋅ ω 0 A 1 ( 3 , 0 ) ⋅ ω 0 A 1 ( 0 , 1 ) ⋅ ω 0 A 1 ( 1 , 1 ) ⋅ ω 1 A 1 ( 2 , 1 ) ⋅ ω 2 A 1 ( 3 , 1 ) ⋅ ω 3 A 1 ( 0 , 2 ) ⋅ ω 0 A 1 ( 1 , 2 ) ⋅ ω 2 A 1 ( 2 , 2 ) ⋅ ω 3 A 1 ( 3 , 2 ) ⋅ ω 6 ] ⏟ ( A 1 ( j 0 , k 0 ) ⋅ ω j 0 k 0 ) ′ \underbrace{\begin{bmatrix}A_1(0, 0) \cdot \omega^0 & A_1(1, 0) \cdot \omega^0 & A_1(2, 0) \cdot \omega^0 & A_1(3, 0) \cdot \omega^0 \\A_1(0, 1) \cdot \omega^0 & A_1(1, 1) \cdot \omega^1 & A_1(2, 1) \cdot \omega^2 & A_1(3, 1) \cdot \omega^3 \\A_1(0, 2) \cdot \omega^0 & A_1(1, 2) \cdot \omega^2 & A_1(2, 2) \cdot \omega^3 & A_1(3, 2) \cdot \omega^6 \\\end{bmatrix}}_{(A_1(j_0, k_0) \cdot \omega^{j_0k_0})^\prime} ( A 1 ( j 0 , k 0 ) ⋅ ω j 0 k 0 ) ′ A 1 ( 0 , 0 ) ⋅ ω 0 A 1 ( 0 , 1 ) ⋅ ω 0 A 1 ( 0 , 2 ) ⋅ ω 0 A 1 ( 1 , 0 ) ⋅ ω 0 A 1 ( 1 , 1 ) ⋅ ω 1 A 1 ( 1 , 2 ) ⋅ ω 2 A 1 ( 2 , 0 ) ⋅ ω 0 A 1 ( 2 , 1 ) ⋅ ω 2 A 1 ( 2 , 2 ) ⋅ ω 3 A 1 ( 3 , 0 ) ⋅ ω 0 A 1 ( 3 , 1 ) ⋅ ω 3 A 1 ( 3 , 2 ) ⋅ ω 6 Finally we multiply the transpose by the ( ω r 1 ) j 1 k 0 (\omega^{r_1})^{j_1k_0} ( ω r 1 ) j 1 k 0
[ ω 0 ω 0 ω 0 ω 0 ω 4 ω 8 ω 0 ω 8 ω 16 ] ⏟ ( ω r 1 ) j 1 k 0 [ A 1 ( 0 , 0 ) ⋅ ω 0 A 1 ( 1 , 0 ) ⋅ ω 0 A 1 ( 2 , 0 ) ⋅ ω 0 A 1 ( 3 , 0 ) ⋅ ω 0 A 1 ( 0 , 1 ) ⋅ ω 0 A 1 ( 1 , 1 ) ⋅ ω 1 A 1 ( 2 , 1 ) ⋅ ω 2 A 1 ( 3 , 1 ) ⋅ ω 3 A 1 ( 0 , 2 ) ⋅ ω 0 A 1 ( 1 , 2 ) ⋅ ω 2 A 1 ( 2 , 2 ) ⋅ ω 3 A 1 ( 3 , 2 ) ⋅ ω 6 ] ⏟ ( A 1 ( j 0 , k 0 ) ⋅ ω j 0 k 0 ) ′ = [ X ( 0 , 0 ) X ( 0 , 1 ) X ( 0 , 2 ) X ( 0 , 3 ) X ( 1 , 0 ) X ( 1 , 1 ) X ( 1 , 2 ) X ( 1 , 3 ) X ( 2 , 0 ) X ( 2 , 1 ) X ( 2 , 2 ) X ( 2 , 3 ) ] ⏟ X ( j 1 , j 0 ) \underbrace{\begin{bmatrix}\omega^0 & \omega^0 & \omega^0 \\\omega^0 & \omega^4 & \omega^8 \\\omega^0 & \omega^8 & \omega^{16} \\\end{bmatrix}}_{(\omega^{r_1})^{j_1k_0}}
\underbrace{\begin{bmatrix}A_1(0, 0) \cdot \omega^0 & A_1(1, 0) \cdot \omega^0 & A_1(2, 0) \cdot \omega^0 & A_1(3, 0) \cdot \omega^0 \\A_1(0, 1) \cdot \omega^0 & A_1(1, 1) \cdot \omega^1 & A_1(2, 1) \cdot \omega^2 & A_1(3, 1) \cdot \omega^3 \\A_1(0, 2) \cdot \omega^0 & A_1(1, 2) \cdot \omega^2 & A_1(2, 2) \cdot \omega^3 & A_1(3, 2) \cdot \omega^6 \\\end{bmatrix}}_{(A_1(j_0, k_0) \cdot \omega^{j_0k_0})^\prime}
= \underbrace{\begin{bmatrix}X(0, 0) & X(0, 1) & X(0, 2) & X(0, 3) \\X(1, 0) & X(1, 1) & X(1, 2) & X(1, 3) \\X(2, 0) & X(2, 1) & X(2, 2) & X(2, 3) \\\end{bmatrix}}_{X(j_1, j_0)} ( ω r 1 ) j 1 k 0 ω 0 ω 0 ω 0 ω 0 ω 4 ω 8 ω 0 ω 8 ω 16 ( A 1 ( j 0 , k 0 ) ⋅ ω j 0 k 0 ) ′ A 1 ( 0 , 0 ) ⋅ ω 0 A 1 ( 0 , 1 ) ⋅ ω 0 A 1 ( 0 , 2 ) ⋅ ω 0 A 1 ( 1 , 0 ) ⋅ ω 0 A 1 ( 1 , 1 ) ⋅ ω 1 A 1 ( 1 , 2 ) ⋅ ω 2 A 1 ( 2 , 0 ) ⋅ ω 0 A 1 ( 2 , 1 ) ⋅ ω 2 A 1 ( 2 , 2 ) ⋅ ω 3 A 1 ( 3 , 0 ) ⋅ ω 0 A 1 ( 3 , 1 ) ⋅ ω 3 A 1 ( 3 , 2 ) ⋅ ω 6 = X ( j 1 , j 0 ) X ( 0 , 0 ) X ( 1 , 0 ) X ( 2 , 0 ) X ( 0 , 1 ) X ( 1 , 1 ) X ( 2 , 1 ) X ( 0 , 2 ) X ( 1 , 2 ) X ( 2 , 2 ) X ( 0 , 3 ) X ( 1 , 3 ) X ( 2 , 3 ) We can observe that the A 1 ( j 0 , k 0 ) A_1(j_0, k_0) A 1 ( j 0 , k 0 ) r 1 r_1 r 1 X ( j 1 , j 0 ) X(j_1, j_0) X ( j 1 , j 0 ) r 2 r_2 r 2 N N N
T = N ( r 1 + r 2 ) T = N(r_1 + r_2) T = N ( r 1 + r 2 ) Recursion
Lets observe one of the DFTs from eq ( 3 ) (3) ( 3 )
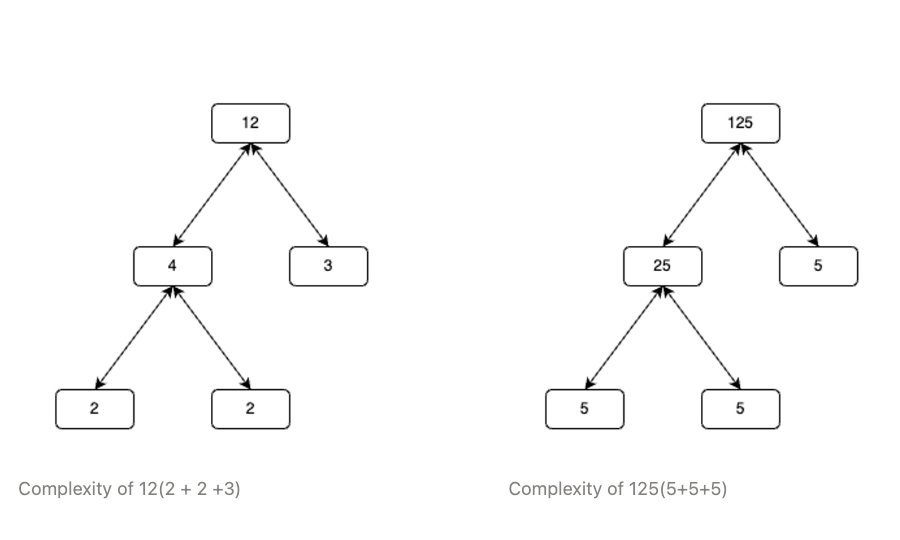
[ ω 0 ω 0 ω 0 ω 0 ω 0 ω 3 ω 6 ω 9 ω 0 ω 6 ω 12 ω 18 ω 0 ω 9 ω 18 ω 27 ] [ A ( 0 ) A ( 3 ) A ( 6 ) A ( 9 ) ] = [ A 1 ( 0 , 0 ) A 1 ( 1 , 0 ) A 1 ( 2 , 0 ) A 1 ( 3 , 0 ) ] \begin{bmatrix}\omega^0 & \omega^0 & \omega^0 & \omega^0 \\\omega^0 & \omega^3 & \omega^6 & \omega^9 \\\omega^0 & \omega^6 & \omega^{12} & \omega^{18} \\\omega^0 & \omega^9 & \omega^{18} & \omega^{27} \\\end{bmatrix} \begin{bmatrix}A(0) \\A(3) \\A(6) \\A(9) \\\end{bmatrix} = \begin{bmatrix} A_1(0, 0) \\ A_1(1, 0) \\ A_1(2, 0) \\ A_1(3, 0) \\\end{bmatrix} ω 0 ω 0 ω 0 ω 0 ω 0 ω 3 ω 6 ω 9 ω 0 ω 6 ω 12 ω 18 ω 0 ω 9 ω 18 ω 27 A ( 0 ) A ( 3 ) A ( 6 ) A ( 9 ) = A 1 ( 0 , 0 ) A 1 ( 1 , 0 ) A 1 ( 2 , 0 ) A 1 ( 3 , 0 ) It’s clear that this is the exact same problem we started with, recall the matrix form of eq ( 1 ) (1) ( 1 ) 2 ⋅ 2 = 2 + 2 2\cdot2 = 2+2 2 ⋅ 2 = 2 + 2 N = 4 N = 4 N = 4 N N N
N = ( r 0 ⋅ r 1 ⋯ r n − 1 ) \begin{split}
N &= (r_0 \cdot r_1 \cdots r_{n-1})
\end{split} N = ( r 0 ⋅ r 1 ⋯ r n − 1 ) Then the complexity of the algorithm becomes:
T = N ( ∑ i = 0 n − 1 r i ) T = N(\sum_{i = 0}^{n-1} r_i) T = N ( i = 0 ∑ n − 1 r i ) The Cooley-Tukey FFT can also be combined with other FFT algorithms like the Good-Thomas FFT for factors that are coprime. This method completely eliminates the need for twiddle factors. Rader’s FFT can also be applied to DFT’s of prime lengths since they have no factors and can’t be decomposed further by the Cooley-Tukey algorithm.
Radix2FFT
What you popularly know as the Radix2FFT is actually another form of the Cooley-Tukey FFT. Since the Cooley-Tukey FFT can be applied recursively. Given the case when N = 2 k N = 2^k N = 2 k
T = 2 k ( 2 0 + 2 1 + ⋯ + 2 k ) = 2 N log 2 N \begin{split}
T &= 2^k(2_0 + 2_1 + \dots + 2_k)\\
&= 2N\log_2 N
\end{split} T = 2 k ( 2 0 + 2 1 + ⋯ + 2 k ) = 2 N log 2 N Inverse FFT
The inverse FFT is the same as the FFT except it’s performed with inverse powers of the generator and finally multiplied by the inverse of the group order. This is given as:
A ( k ) = 1 N ∑ j = 0 N − 1 X ( j ) ⋅ ω − j k k = 0 , 1 , … N − 1. A(k) = \frac{1}{N}\sum^{N-1}_{j=0}X(j) \cdot\omega^{-jk} \quad k = 0,1,\dots N-1. A ( k ) = N 1 j = 0 ∑ N − 1 X ( j ) ⋅ ω − j k k = 0 , 1 , … N − 1. (Proof is left as an exercise for the reader)
References
[ 1 ] ^{[1]} [ 1 ] An Algorithm for the Machine Calculation of Complex Fourier Series. James W. Cooley and John W. Tukey